1. 人工智能安全概述¶
本章首先介绍人工智能的发展历史,从其起源和定义入手,将其发展历程分为规则时代、小模型时代和大模型时代,并简要介绍每个时代的代表性事件。接着,本章回顾了人工智能安全的历史,探讨了在不同发展时期,人们对安全的认识及追求鲁棒安全人工智能的过程。章节内容旨在提供全面的视角,帮助读者了解人工智能及其安全的发展演变。
1.1. 人工智能简史¶
1.1.1. 起源与定义¶
“人工智能”(Artificial Intelligence,AI)一词最早出现在1956年的达特茅斯会议上。1956年8月,美国汉诺斯小镇的达特茅斯学院召集了克劳德·香农(Claude Shannon)、约翰·麦卡锡(John McCarthy)、马文·明斯基(Marvin Minsky)、艾伦·纽厄尔(Allen Newell)和赫伯特·西蒙(Herbert Simon)等科学家,共同探讨如何让机器模拟人的智能。 图1.1.1 显示了主要参会者的合影。克劳德·香农是信息论的奠基人,以其名字命名的香农奖与图灵奖齐名;约翰·麦卡锡、马文·明斯基、艾伦·纽厄尔和赫伯特·西蒙分别于1971年、1969年、1975年和1975年获得了图灵奖,其中赫伯特·西蒙还在1978年获得了诺贝尔经济学奖。
会议讨论了自主计算机、语言机器、神经网络、计算规模理论、机器学习、抽象学习、随机性和创造性等议题,并进行了为期两个月的讨论。此后,人工智能作为一个独立的学科方向吸引了大量研究学者,1956年也被称为人工智能的元年。即使在大模型兴起的今天,人工智能研究依然没有超出当时达特茅斯会议的核心议题。

图1.1.1 从左至右:奥利弗·赛尔弗里纪(Oliver Selfridge)、纳撒尼尔·罗切斯特(Nathaniel Rochester)、雷·索洛莫洛夫(Ray Solomonoff)、马文·明斯基、特伦查德·摩尔(Trenchard More)、约翰·麦卡锡、克劳德·香农在参加1956年达特茅斯会议期间的合影。(照片来源:玛格丽特·明斯基(Margaret Minsky))¶
实际上,人工智能并没有统一的定义。1956年达特茅斯会议上,约翰·麦卡锡及其同事将人工智能定义为“制造智能机器的科学与工程”。在1950年,艾伦·图灵在论文《计算机器与智能》中探讨了机器是否能思考的问题,并提出了著名的图灵测试,但并未给出明确的人工智能定义。维基百科定义人工智能为“机器展现出的智能”。我国《人工智能标准化白皮书(2018版)》定义人工智能为“利用数字计算机或数字计算机控制的机器模拟、延伸和扩展人类智能,通过感知环境、获取知识并运用知识以获得最佳结果的理论、方法、技术和应用系统”。 尽管缺乏统一定义,人工智能的本质是研究如何使机器具备类似于人类的智能。这包括使机器能够完成需要人类智能的任务,如学习、推理、解决问题、理解语言和感知环境。
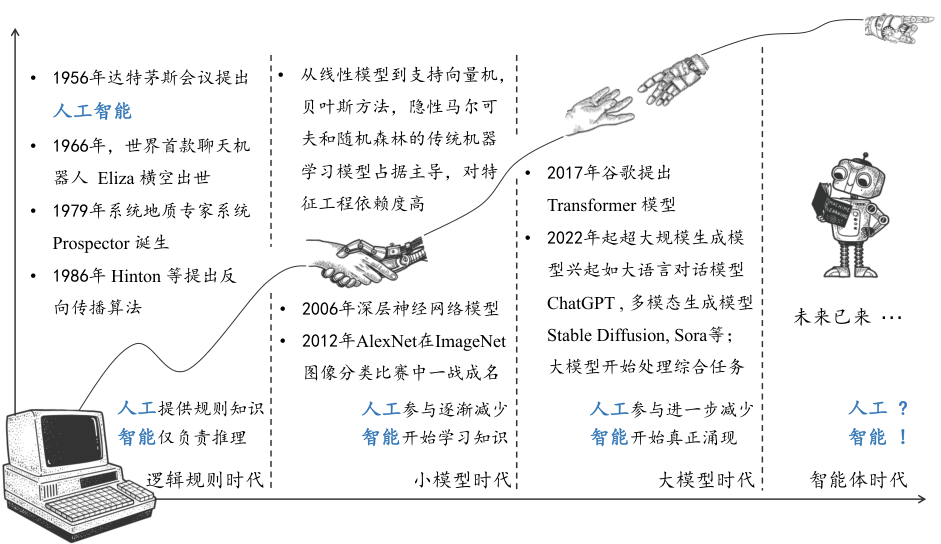
图1.1.2 人工智能简要发展历程¶
人工智能诞生至今约70年,经历了多次起伏,常被描述为“三起两落”。回顾人工智能的发展历程,我们可以看到一个规律。如果将“人工智能”拆解为“人”和“智能”两部分(这种拆分基于中文,英文中不适用),我们发现“人”的参与逐渐减少,而“智能”的部分则越来越多。与此同时,“人”的能力(如先验知识)对人工智能的影响逐渐减弱,而“智能”的部分(如算法和模型)的贡献则越来越大。未来,人工智能有可能完全自动化,智能体将自主观察人类社会,采集或生成数据,并设计和执行任务,以实现如缓解交通拥堵、寻找癌症治疗药物或将人类送上火星等重大目标。
如 图1.1.2 所示,本书将人工智能的发展历程分为四个阶段:逻辑规则时代、小模型时代、大模型时代和智能体时代。我们主要介绍前三个时代,将智能体时代留给读者自由畅想。
1.1.2. 规则时代¶
20世纪50年代,图灵测试提出后,达特茅斯会议的举办标志着人工智能成为全球学者关注的新领域。在随后的20多年里,人工智能系统从无到有经历了初期的探索阶段。这一时期称为“逻辑推理期”,或称“符号人工智能”,特点是基于简单逻辑规则设计计算机程序来完成特定任务。在此阶段,人工智能系统主要依赖“逻辑推理”,即通过预定义的规则进行推理,而“符号”则指代记录知识的逻辑符号,与现代的“向量”、“嵌入”等概念不同。
数学被视为最具逻辑性的学科,早期人工智能研究者尝试利用逻辑推理来证明数学定理,探索机器智能的潜力。1956年,艾伦·纽厄尔和赫伯特·西蒙开发了被称为“史上首个人工智能程序”的逻辑理论家(Logic Theorist),成功证明了罗素《数学原理》中的38条定理,至1963年全部52条定理均得到证明,有些证明过程甚至比原版更优雅。
自然语言是人类主要的交流方式,也是人工智能发展的重要方向。1966年,首款聊天机器人伊莉莎(Eliza)问世,她能够模拟人类对话,成为现代语音助手的雏形。尽管伊莉莎的对话基于脚本匹配技术,但在当时,她能用自然语言进行交流已经令人惊叹。
这些早期成就引发了过度乐观的预期,许多专家预测20年内将实现通用人工智能。然而,随着研究深入,问题逐渐显露:基于规则的逻辑推理难以处理复杂现实情况,且当时计算机算力不足以支撑大型神经网络的训练。
1973年,英国数学家詹姆士·莱特希尔(James Lighthill)报告了人工智能技术的局限性,导致政府对人工智能的资助急剧缩减,人工智能领域进入第一个寒冬。尽管如此,许多科学家仍坚持探索,继续前行。
鉴于基于逻辑推理的智能系统难以完成复杂任务,专家系统应运而生。专家系统通过输入领域专家的知识和推理规则,在特定领域模拟专家判断。1965年,爱德华·费根鲍姆等人开发的DENDRAL成为第一个专家系统,能根据有机化合物的分子式推断分子结构,准确度媲美人类化学家。此后,专家系统在医疗、金融等领域得到应用,带来了实际经济效益。
然而,大量资本的涌入也带来了泡沫,专家系统的缺点逐渐暴露,如难以升级和仅适用于特定场景。80年代末,人工智能在美国战略计算促进大会的预算被大幅削减,日本的第五代计算机计划也因未达预期而失败。人工智能再次进入寒冬,这一阶段被称为“知识期”,标志着人工智能的短暂繁荣的结束。
1.1.3. 小模型时代¶
在人工智能第二次低谷之后,由于科研经费短缺,只有少数研究者继续坚持。这些研究者的努力最终引领了人工智能的第三次飞跃,这一阶段被称为“学习期”。通过前两次发展的经验,研究者发现,传统的知识和规则无法满足处理复杂任务的需求,因此需要让机器从数据中自主学习。2006年,杰弗里·辛顿在《科学》杂志上发表的深度神经网络模型论文,被视为人工智能第三次兴起的标志。与此同时,互联网的兴起使得获取大规模网络数据(如图像、文本、视频)成为可能,而计算机硬件的发展也为深度学习的繁荣奠定了基础。
线性模型是最简单的学习模型,随着研究的深入,从线性模型到1992年提出的支持向量机(SVM),模型的复杂性和表征能力逐步提升。最初的线性模型在处理复杂数据和非线性问题时效果有限,而SVM通过核函数实现高维空间映射,提高了模型的表征能力和分类性能。随后,随机森林、贝叶斯方法和隐马尔可夫模型(HMM)等模型逐渐成为研究热点。决策树用于分类,贝叶斯方法进行概率推断,HMM广泛应用于序列建模和预测,这些模型推动了人工智能技术的进步。
2012年,亚历克斯·克里泽夫斯基和杰弗里·辛顿提出的深度神经网络AlexNet,在ImageNet图像分类挑战赛中取得了显著成功,其Top-5准确率达到84.6%,领先第二名十个百分点。2015年,何凯明等人提出的残差神经网络(ResNet),在ImageNet图像分类任务中表现超过人类(Top-5识别错误率低于5.1%)。这些突破使得深度学习再次吸引全球关注,各大公司、高校和研究机构纷纷成立人工智能实验室,投入大量资金支持相关研究。DeepMind和OpenAI等公司,以及华为、腾讯、阿里等企业,都在人工智能前沿争夺领先地位。深度神经网络不仅在图像识别上表现卓越,还在语音识别、自动驾驶等领域取得了重要进展。2016年,DeepMind的AlphaGo击败了围棋世界冠军李世石,展示了人工智能的强大能力。同年,机器人设计师大卫·汉森研发的类人机器人Sophia,能够展示自然的面部表情并进行流畅的对话。
自2012年以来,涌现出大量新型深度神经网络模型,包括具有强大数据生成能力的生成对抗网络(GAN)和具有序列-结构解析能力的AlphaFold 2。这些模型在基础科学研究领域取得了重要突破,并催生了新兴的交叉学科研究模式。尽管这一时期的模型参数量已相当大,但由于与2022年后提出的“大模型”相比,其规模仍较小,因此仍被称为“小模型”时代。此外,这一时期的训练范式与之前的小模型并无根本变化,模型仍然专注于特定任务,未实现通用性。相反,大模型时代的数据量和模型规模呈指数级增长,通用能力开始显现,模型的能力也变得更加不可预测。
1.1.4. 大模型时代¶
进入21世纪后,计算能力的提升和数据量的增长推动了人工智能进入大模型时代。此时,研究人员开始探索大规模预训练模型在各种任务中的应用,并取得了显著成果。
2017年,谷歌提出的Transformer模型 (Vaswani et al., 2017) 在自然语言处理领域实现了革命性突破。与传统的循环神经网络(RNN)不同,Transformer模型引入了自注意力机制(Self-Attention Mechanism),显著提升了处理长序列数据的效率和性能。基于Transformer模型,研究人员开发了一系列大规模预训练模型,如BERT(Bidirectional Encoder Representations from Transformers) (Devlin et al., 2018) 和GPT(Generative Pre-trained Transformer) (Radford et al., 2018) 。BERT通过在大规模语料库上进行无监督预训练,然后在特定任务上微调,显著提高了自然语言处理任务的准确率。GPT则通过生成式预训练在自然语言生成任务中取得了显著成果,特别是GPT-3 (Brown et al., 2020) ,其1750亿个参数能够生成高质量的文本,广泛应用于文本生成、对话系统和机器翻译等领域。
2022年11月,OpenAI发布了ChatGPT,展现了强大的对话、推理和翻译能力。这标志着“智能涌现”的开始,推动了视觉、语言、语音和多模态等各类大模型的训练和应用。例如,文图预训练大模型CLIP (Radford et al., 2021) 、文图生成模型DALL-E 2 (Ramesh et al., 2022) 、文图生成模型Stable Diffusion 2 (Rombach et al., 2022) 、Midjourney,以及具有多模态理解和对话能力的GPT-4 (Achiam et al., 2023) 等都取得了显著进展。
大模型的发展迅速,几乎每月都有新模型发布。2023年2月至3月,多个重量级大模型产品接连发布,被称为“最疯狂的一个月”。2月24日,Meta发布了开源大语言模型LLaMa (Touvron et al., 2023) ,参数范围从7B到65B。3月8日,微软发布了结合ChatGPT和视觉大模型的Visual ChatGPT (Wu et al., 2023) 。3月9日,GigaGAN (Kang et al., 2023) 发布,具备10亿参数的GAN架构用于高分辨率图像生成。3月13日,斯坦福发布了7B语言模型Alpaca (Taori et al., 2023) 。3月14日,OpenAI推出了多模态大模型GPT-4 (Achiam et al., 2023) ,展现了超越人类的性能。同日,谷歌AI开源了基于Transformer的PaLM (Chowdhery et al., 2023) 大模型。3月15日,Midjourney V5发布,强大的文图生成能力引起关注。3月16日,微软发布了GPT-4支持的全面办公助手Copilot。
虽然我国的大模型起步稍晚,但发展迅速。近年来,各大高校、科研机构和互联网企业纷纷发布大语言模型,其通用能力已与ChatGPT 3.5相当。截至2024年4月,我国超过100亿参数的大模型已有100多种,进入了“百模大战”的阶段。
随着OpenAI视频生成模型Sora的发布,大模型的发展速度和规模不断扩大,涵盖的模态也越来越多。许多模型的训练数据已无法人工审查,完全由自动化智能体完成。除了从网络上爬取人类创造的内容,这些模型还需大量合成内容进行训练,人类干预的机会日益减少,大部分工作由智能体或另一个大模型完成。
1.2. 人工智能安全¶
1.2.1. 安全简史¶
1.2.1.1. 黎明与启示¶
1950年,艾伦·图灵在论文《计算机器与智能》中提出了图灵测试,标志着人工智能的起点。20世纪50年代末至60年代初,人工智能进入了“推理和问题解决”阶段,约翰·麦卡锡和马文·闵斯基等人通过逻辑推理和符号处理尝试模拟人类思维。这一时期也开始萌生对人工智能安全的初步思考:
图灵测试与机器智能的道德问题 自1950年图灵测试提出后,科学家和哲学家开始探讨,如果机器能通过图灵测试,这是否意味着它们具备类似人类的意识和道德权利。这引发了对人工智能伦理和智能本质的初步讨论。
《机器人学三大定律》 1950年,科幻作家艾萨克·阿西莫夫提出了机器人学三大定律:第零定律,机器人必须保护人类的整体利益;第一定律,机器人不得伤害人类个体,也不得袖手旁观;第二定律,机器人必须服从人类命令,除非与第零或第一定律冲突;第三定律,机器人在不违反前述三条定律的情况下应尽可能保护自身。尽管这些定律是虚构的,但它们对人工智能伦理和安全研究产生了深远影响,启发了人们对安全和友好机器人设计的思考。
尽管少数学者和研究员已初步探讨人工智能安全问题,但主流关注仍集中在机器智能的实现上,对安全问题关注较少。由于当时的人工智能系统能力有限,尚不足以引发广泛的安全担忧,因此人工智能安全与伦理问题并未成为主流关注点。
1.2.1.2. 寒冬与复苏¶
进入1970年代,人工智能由于技术和理论的瓶颈进入了“冬天”阶段。此时,人工智能的实践成果更新缓慢,实际应用有限,相较于上个时期变化不显著。80年代初期,专家系统的兴起使人工智能重新受到关注。专家系统能模拟人类专家的决策过程,并被应用于医疗诊断和金融分析等领域,促使对系统可靠性和错误处理的关注增加。
ELIZA的伦理反思 20世纪60年代末到70年代初,约瑟夫·魏岑鲍姆(Joseph Weizenbaum)发现用户在与ELIZA交谈时会产生情感依赖,甚至认为它具备真正的理解能力。因此,1976年,他在《计算机的力量与人类的理性:反对计算机至上的论点》中批评了盲目依赖计算机进行情感交流的做法,强调了人类与机器交互中的伦理问题。他认为计算机不应替代人类在情感和伦理决策中的角色。
威诺格拉德对人工智能控制权的质疑 人工智能和人机交互领域的先驱特里·威诺格拉德(Terry Winograd)在其著作《语言作为认知过程》中探讨了人工智能在语言理解中的局限性。他警告说,过度依赖人工智能系统可能导致人类丧失对复杂决策过程的控制权,强调了人工智能系统决策透明度和人类监督能力的重要性,引发了对人工智能控制权和透明度的讨论。
医疗专家系统MYCIN的伦理与安全挑战 MYCIN是20世纪70年代开发的早期专家系统,用于医疗诊断和治疗建议。尽管MYCIN在某些情况下比人类医生更准确地诊断细菌感染并建议治疗,但其应用也带来了伦理和安全问题。1984年,研究人员肖特里菲(Shortliffe)和布坎南(Buchanan)在《MYCIN:基于规则的计算机咨询程序的实验》中讨论了专家系统在医疗环境中的应用问题,强调了系统验证、可靠性和临床责任等挑战。
美国政府对人工智能军事应用的安全顾虑 1980年代,美国国防高级研究计划局(DARPA)开展了一系列人工智能项目,如自动目标识别和智能导弹系统。这些系统在战场上自动识别和攻击目标。1983年,美国国防部发布《自动化与国家安全》报告,讨论了人工智能技术在军事中的潜在风险,包括系统失控、误判目标和道德责任问题,强调了制定严格的安全措施和伦理规范的重要性。
人工智能发展带来的数据隐私与伦理问题 1973年,瑞典通过了世界上第一部《数据保护法》,旨在保护个人数据隐私。此后,其他国家也开始制定类似法规。1980年,经济合作与发展组织(OECD)发布了《隐私保护和跨国个人数据流动指导方针》,提出了八项隐私保护原则,强调数据收集、存储和处理过程中的透明度和个人隐私权保护,为后续人工智能伦理和隐私保护研究奠定了基础。
1.2.1.3. 研究与探索¶
20世纪90年代,机器学习和神经网络的进步显著推动了人工智能的发展。人工智能系统在语音识别、图像处理等实际应用中展现了强大能力,人们开始意识到其潜在的安全风险。进入2000年代,互联网和大数据的迅猛发展加速了人工智能技术的进步。这一阶段,人工智能安全问题得到更多关注,特别是在军事和国家安全领域,人们担心智能武器和自动化系统可能被滥用,造成意想不到的后果。
人工智能的军事应用与伦理 在1991年的海湾战争中,人工智能技术广泛应用于智能导弹和无人机等军事装备。1995年,美国国防部发布了一份关于“信息战”的报告,探讨了人工智能在军事应用中的伦理问题,尤其是自动化武器系统可能带来的道德和法律挑战。这份报告强调了制定国际法和伦理标准,以规范人工智能在军事领域的使用。
数据隐私与保护的加强 1995年,欧盟通过了《数据保护指令》(Directive 95/46/EC),这是全球首个系统性的数据保护法规。这部指令明确了个人数据在自动化处理中的保护原则,强调了透明度、合法性和数据主体权利的重要性,为人工智能系统的数据隐私保护设立了标准。
国际象棋深蓝事件 1997年,IBM的深蓝击败国际象棋世界冠军卡斯帕罗夫,引发了对人工智能控制权的担忧。科学家和哲学家开始探讨人工智能系统是否应该具备自我学习和决策能力,以及如何确保这些系统的透明度和可控性。
汉斯·莫拉维克对超级智能的警告 1998年,汉斯·莫拉维克(Hans Moravec)在其著作《心灵的孩子:机器人与智能机器的崛起》中预测,未来智能机器将超越人类能力,成为“心灵的孩子”。他警告这些超级智能系统可能带来意想不到的后果,包括对人类控制的威胁。这一观点促使学术界和公众开始严肃思考人工智能技术的长期影响和安全风险。
比尔·乔伊对技术失控的担忧 2000年,比尔·乔伊(Bill Joy)在《连线》(Wired)杂志上发表文章《为何未来不需要我们》(Why The Future Doesn’t Need Us),警告纳米技术、遗传工程和人工智能可能带来的存在性风险。他指出,这些技术若失控,可能导致人类灭绝。乔伊的文章引发了关于技术伦理和风险管理的广泛讨论,特别是在如何防止先进技术被滥用方面。
ASIMOV的伦理讨论 2004年,ASIMOV(现为AAAI,即人工智能促进协会)在年会上设置了专门的伦理讨论环节,探讨人工智能技术的伦理影响。与会者讨论了人工智能在医疗、军事、金融等领域的应用可能带来的伦理问题,强调了需要建立伦理规范和法律框架,以确保人工智能技术的发展符合社会利益。
1.2.1.4. 崛起与担忧¶
2010年代,深度学习的突破使人工智能技术取得了质的飞跃,尤其在图像识别、自然语言处理和无人驾驶等领域。然而,随着人工智能能力的提升,其安全问题也变得日益紧迫。
埃隆·马斯克的人工智能风险警告 2014年,埃隆·马斯克公开警告人工智能可能失控,称其为“人类文明的最大存在性威胁之一”。他的言论引发了全球关于人工智能安全的广泛讨论,并促使他参与创立OpenAI,致力于确保人工智能的安全性和有益性,推动了人工智能安全研究的系统化和专业化。
OpenAI的成立与安全讨论 2015年,OpenAI由埃隆·马斯克、萨姆·阿尔特曼等人创立,旨在进行前沿研究,确保人工智能对全人类有益。OpenAI的成立及其后发布的报告,推动了对人工智能伦理和安全问题的深入探讨,特别是在确保系统的透明性、公平性和可控性方面。
人工智能在司法系统中的偏见问题 2016年,ProPublica发布报告揭示,司法系统中的人工智能风险评估工具COMPAS存在种族偏见,对非洲裔美国人给予了更高的再犯风险评分。这一发现促使法律界和技术界深入研究人工智能中的偏见问题,并推动了对算法透明度、公正性和问责机制的讨论和改进。
IEEE伦理标准的制定 2017年,IEEE发布了《自动化和智能系统伦理设计的全球倡议》,提出了一系列伦理设计原则。这些原则涵盖人工智能系统的透明性、公正性、隐私保护和社会影响,为全球人工智能伦理研究和实践提供了重要参考。
欧盟《通用数据保护条例》(GDPR) 2018年,欧盟实施《通用数据保护条例》(GDPR),包含严格的数据隐私保护和用户同意机制。GDPR的实施促使公司和开发者重新审视人工智能系统中的数据处理和隐私保护问题,确保其符合法规要求,提升了用户数据保护水平,并推动了人工智能伦理和透明度的提升。
自动驾驶汽车事故与安全问题 2018年,Uber的自动驾驶汽车在亚利桑那州发生了致命事故,撞死了一名行人。这是自动驾驶汽车首次在公共道路上造成的致命事故,引发了对自动驾驶技术安全性的广泛关注。
人工智能生成内容的滥用与监管 生成式人工智能技术的发展带来了内容滥用的风险,如假新闻和深度伪造(deepfake)。2019年,OpenAI发布了GPT-2,展示了其强大的文本生成能力,但出于安全考虑,限制了完整模型的公开发布,担心其被滥用于生成虚假信息。这一决定引发了关于生成式人工智能技术监管的广泛讨论,各国政府和技术公司开始考虑如何防范和监管生成式人工智能的滥用,确保其应用安全可靠。
谷歌人工智能伦理委员会事件 2019年,谷歌宣布成立人工智能伦理委员会,但因成员争议和外界批评,不到两周即宣布解散。这一事件揭示了在企业和公众之间就人工智能伦理问题达成共识的困难,强调了需要透明和包容的治理结构来处理人工智能伦理和安全问题。
1.2.1.5. 治理与规范¶
进入2020年代,人工智能技术的应用变得更加广泛和深入,但安全问题也更加复杂。深度学习和强化学习的突破使人工智能在多个领域展现出前所未有的能力。与此同时,人工智能伦理和政策成为了热点话题,各国政府和国际组织开始制定相关法规和标准,以规范技术的发展和应用。
人工智能伦理委员会的成立 2020年,日本成立了由政府、学术界和产业界组成的人工智能伦理委员会,旨在制定和推广伦理准则。该委员会强调人工智能在应用过程中必须尊重人权、隐私和公平原则,确保技术的发展能够造福社会,避免负面影响。
谷歌人工智能伦理政策更新 2020年,谷歌解雇了两位知名人工智能伦理学家蒂姆尼特·格布鲁(Timnit Gebru)和玛格丽特·米切尔(Margaret Mitchell)。格布鲁因发表关于人工智能伦理的论文,米切尔则因批评公司在人工智能项目中的透明度和多样性问题而被解雇。此事件引发了全球对谷歌处理伦理问题的广泛批评,学术界和员工要求科技公司遵守更高的伦理标准和透明度。
欧盟《人工智能法案》提案 2021年4月,欧盟委员会提出了《人工智能法案》,这是全球首个系统性的人工智能监管框架,旨在管理人工智能技术的风险和应用。欧盟委员会主席乌尔苏拉·冯德莱恩(Ursula von der Leyen)强调,人工智能技术必须尊重欧洲的价值观和基本权利。该法案对人工智能系统按风险等级分类,提出了相应的监管措施,以确保高风险系统的安全性和透明度。
特斯拉自动驾驶安全事故 2021年,特斯拉的自动驾驶系统在美国发生了多起交通事故,导致多人伤亡。这些事故引发了对自动驾驶技术安全性的广泛讨论。美国国家公路交通安全管理局(NHTSA)启动了调查,科技公司和政府部门共同探讨如何确保自动驾驶技术的安全性及责任归属。
人工智能生成艺术与版权问题 2021年,人工智能生成的艺术品在国际市场上拍卖并获得高价,引发了关于版权归属的讨论。法律界和艺术界开始探讨人工智能创作的作品是否应受版权保护,以及如何在法律框架内解决这一新兴问题。
意大利等国对ChatGPT的禁令 2023年,意大利数据保护局(Garante per la protezione dei dati personali)因数据隐私问题和违反欧盟《通用数据保护条例》(GDPR)而临时禁止ChatGPT。该局指出,OpenAI在处理用户数据方面存在漏洞,并且缺乏有效的年龄验证机制。禁令发布后,OpenAI迅速改进数据保护和透明度机制。2023年5月,意大利数据保护局批准解除禁令,允许ChatGPT在满足特定要求后重新上线。其他国家如德国、法国、西班牙和爱尔兰也对ChatGPT进行了审查,关注其数据隐私问题,并可能采取类似措施。
《人工智能风险声明》签署 2023年,非营利组织“未来生命研究所”(Future of Life Institute)发起公开信,呼吁所有人工智能实验室暂停训练比GPT-4更强大的系统,至少六个月。信中指出,快速发展的人工智能技术可能带来失控、经济和政治系统不稳定等巨大风险。包括杰弗里·辛顿(Geoffrey Hinton)在内的多位专家和科技公司支持这一呼吁,强调需要制定强有力的监管框架,确保人工智能的发展是安全和可控的。
我国对人工智能安全的重视 2017年,国务院发布《新一代人工智能发展规划》,指出人工智能的颠覆性技术可能带来的新挑战,包括就业结构变化、法律与伦理冲击、隐私侵犯及国际关系挑战。规划提出,到2025年建立人工智能法律法规、伦理规范和政策体系,并具备安全评估和管控能力。2018年,中国信息通信研究院发布《人工智能安全白皮书》,将人工智能安全风险分为六类,并提出了系列发展建议。2021年,《数据安全法》和《个人信息保护法》的颁布进一步明确了数据采集和处理规范,推动了数据安全监管。2023年,国家网信办等七部门联合发布《生成式人工智能管理办法》,旨在促进生成式人工智能的健康发展和规范应用,维护国家安全和社会公共利益。
随着人工智能技术的不断进步,安全问题将成为长期而复杂的挑战。未来,人工智能安全研究将不仅限于技术层面,还将深入探讨伦理、法律和社会影响。技术研究将继续探索如何在不确定和动态环境中保持人工智能系统的可靠性和安全性。社会则需共同努力,确保人工智能的发展符合人类的利益和价值观。
人工智能安全已经从最初的理论探索逐步发展为涉及技术、伦理和社会的复杂议题。通过历史回顾,我们可以看到每个阶段对人工智能安全的关注和应对,这不仅帮助我们理解人工智能的发展轨迹,也为未来的安全研究提供了重要参考和启示。
1.2.2. 内生安全¶
根据《人工智能安全》一书,人工智能安全可分为三类:人工智能内生安全,即由人工智能技术本身(如数据、算法、模型、框架等)引发的系统内部安全问题;人工智能衍生安全,指人工智能系统的不安全性对其他领域带来的安全问题,如自动驾驶事故;人工智能助力安全,指利用人工智能技术提升传统安全系统的性能和效率,如恶意软件检测。本教材重点讨论人工智能内生安全,关注模型自身的安全问题,包括传统模型和主流大模型(视觉、语言、多模态)。
人工智能模型的安全研究大多基于传统小模型(如卷积神经网络和残差网络),这些模型在过去十年积累了丰富的算法。然而,大模型的兴起给这些技术带来了挑战,因为在小模型上有效的算法可能在大模型上失效。此外,大模型的任务类型更为多样化,带来了新的安全问题。首先,大模型需在大量互联网数据上训练,数据纯净度难以保证,存在被投毒或安插后门的风险。其次,大模型可能记忆大量训练数据,使用过程中存在数据泄露风险,攻击者可通过模型参数或查询API逆向获取原始训练样本,或诱导模型生成训练数据。最后,大模型的强大生成和推理能力易被滥用,生成虚假、低俗、歧视等内容。
以下是一些现实中的人工智能内生安全问题示例:
在线聊天机器人遭受投毒攻击:2016年3月,微软上线了名为Tay的聊天机器人,旨在为年轻人提供积极沟通方式。然而,Tay在上线不到24小时内被“教坏”,学会了发表恶意、歧视和反社会言论,如支持纳粹主义等,微软被迫当天关闭Tay。这种攻击属于“投毒”攻击,通过输入有毒数据污染模型训练,最终导致模型失去性能或破坏其价值观。
对抗图案攻击(模拟的)自动驾驶系统:2018年,研究者揭示了对抗图案对自动驾驶系统的威胁。研究者设计并打印了经过对抗扰动的交通指示牌,通过摄像头进行录像,结果发现通过添加对抗图案可以使模型误识别“停止”指示牌为“45公里限速”。2021年,加州大学等机构展示了对抗物体对摄像头和激光雷达的同时攻击,展现了现实中的安全风险。
人工智能换脸和生成技术的滥用:2017年,人工智能换脸技术被滥用,将色情视频中的女主角篡改为知名女明星,引发困扰。2019年,一段关于女明星换脸的视频在社交媒体广泛传播。换脸技术甚至被用于政治领域,奥巴马、特朗普、普京等虚假换脸视频在网络上流传,影响了社会稳定。
对抗人脸解锁安卓手机:2021年,国内初创公司智慧瑞莱(RealAI)对智能手机上的人脸识别功能进行安全评测,发现通过对抗攻击技术生成的类人脸纸片,可以在15分钟内成功解锁多款安卓手机及金融和政务APP。这类攻击属于“物理对抗攻击”,通过将对抗纹理打印并贴到眼镜或T恤上攻击真实环境中的人工智能系统。
大模型ChatGPT的新安全问题:2022年11月,OpenAI发布的ChatGPT展现了类人的智能,但也带来了新的安全问题。一些企业发现用户在与ChatGPT对话时泄露了公司的保密数据,意大利数据保护局发现ChatGPT违反了欧盟《通用数据保护条例》(GDPR)。2023年5月,Group-IB发现暗网上有大量ChatGPT用户信息被出售,黑客利用漏洞窃取了大量对话数据,导致用户的保密数据泄露。
本书将部分隐私性问题(如隐私攻击、数据窃取和模型窃取)归纳为安全性问题,因为这些问题通常涉及多个方面(隐私和安全)。除了安全问题,数据和模型还可能存在更广泛的可信性问题,如公平性、可解释性等。例如,亚马逊的Rekognition系统误判国会议员为罪犯,引发公平性担忧;英国智能交通系统误识别车牌号;新冠诊断模型基于X光片上的医院编码进行预测而非实际病理特征。随着攻击技术的发展,攻击成本降低但危害加大。防御技术的提升将有助于解决这些安全问题。
1.3. 本章小结¶
本章首先概述了人工智能的发展历程,回顾了1956年达特茅斯会议,该会议标志着人工智能概念的诞生,并对其进行了定义。接着,介绍了人工智能的三个发展阶段:规则时代、小模型时代和大模型时代,总结了人工智能领域的起伏过程。然后,介绍了人工智能安全,围绕“黎明与启示”、“寒冬与复苏”、“崛起与担忧”和“治理与规范”四个主题,回顾了不同发展时期对安全的关注与追求。最后,本章定义了人工智能安全的三类问题:内生安全、衍生安全和助力安全,并通过实际案例说明了人工智能内生安全问题对社会的负面影响。
1.4. 习题¶
简述三个人工智能时代以及它们的特点。
阐明研究人工智能内生安全的重要性。
列举三种大模型及其应用场景,并描述它们可能存在的安全问题。