7. 多模态大模型安全¶
近年来,多模态大模型逐渐受到关注。这些模型不仅处理文本,还融合了图像、视频、音频等多种模态。流行的模型包括视觉语言预训练(Vision-Language Pre-training,VLP)模型,如 CLIP (Radford et al., 2021) 和 ALBEF (Li et al., 2021) ;文本生成图像(Text-to-Image,T2I)模型,如 Stable Diffusion (Rombach et al., 2022) ;以及视觉语言模型(Vision Language Model,VLM),如 LLaVA (Liu et al., 2023) 、MiniGPT-4 (Zhu et al., 2023) 、InstructBLIP (Dai et al., 2023) 和 GPT-4 (Achiam et al., 2023) 。
正如人类通过视觉和语言与世界互动,每种模态在表达和交流中都具有独特优势。融合这些模态可以更全面地理解世界,实现语言和视觉的综合理解和表达,接近通用人工智能的目标。然而,虽然多模态大模型展现了许多令人兴奋的应用前景,它们也带来了显著的安全隐患。多模态的引入就像在房屋中增加了额外的门,为各类攻击提供了更多入口,创造了新的攻击面。
7.1. 对抗攻击¶
本节介绍针对视觉语言预训练模型CLIP和视觉语言模型(VLM)的对抗攻击算法。
7.1.1. 攻击CLIP模型¶
针对 CLIP 的对抗攻击研究探讨了如何通过恶意干扰文本和图像输入来破坏模型性能。作为一种强大的多模态模型,CLIP 通过联合学习文本和图像的嵌入,表现出色。然而,这种跨模态特性使其易受到对抗攻击。本节将介绍三种代表性的 CLIP 对抗攻击算法:Co-Attack、SGA 和 AdvCLIP。这些算法通过扰动文本和图像双模态来破坏“文本-图像”嵌入的对齐,但采用了不同的扰动方法。这种对齐的破坏会导致下游任务中的严重识别错误。
协同攻击(Co-Attack) (Zhang et al., 2022) 是一种既可以攻击单模态又可以攻击多模态的对抗攻击方法。其目标是通过对抗扰动造成两类对齐错误:图像-文本对齐错误和多模态对齐错误。由于Co-Attack的灵活性,它适用于融合VLP(如ALBEF)模型和对齐VLP(如CLIP)模型。
在针对融合 VLP 模型的攻击中,为了克服连续图像模态和离散文本模态之间的输入表示差异,Co-Attack 采用了逐步的方案:首先扰动离散的文本输入,然后在给定文本扰动的情况下扰动连续的图像输入。这是因为在离散空间中优化设计目标较为困难,因此 Co-Attack 从文本模态开始扰动,并以此为准则,随后对图像模态进行扰动。通过 BERT-Attack (Li et al., 2020) ,对文本 \({\boldsymbol{x}}_t^{\prime}\) 的对抗攻击可以表示为:
其中,\(E_i(·,·)\)是图像嵌入,\(E_t(·,·)\)是文本嵌入,\(E_m(·,·)\)是多模态嵌入,对图像模态\({\boldsymbol{x}}_i\)的对抗攻击则进行如下操作:
其中,\(\mathcal{L}\)使用了KL损失,\(\alpha_1\)是一个超参数,控制第二项的贡献。上述优化问题可以通过类似于PGD的算法解决。
对于单模态嵌入的攻击,Co-Attack 旨在使扰动后的图像模态嵌入远离扰动后的文本模态嵌入。需要注意的是,单模态嵌入空间与多模态嵌入空间不同:在单模态嵌入空间中,图像和文本具有各自独立的表示,而在多模态嵌入空间中,它们共享一个共同的表示。与多模态嵌入攻击类似,Co-Attack 首先扰动文本输入,然后对图像模态进行对抗攻击:
其中,\(\alpha_2\)是一个超参数,控制第二项的贡献。
集合引导攻击(Set-level Guidance Attack, SGA) (Lu et al., 2023) 通过利用多个“图像-文本”对之间的跨模态交互,旨在解决对抗攻击迁移性较差的问题。SGA的提出者认为,低迁移性部分是由于对跨模态交互的利用不足。与单模态学习不同,VLP模型高度依赖跨模态交互,多模态对齐通常是多对多的,例如,一幅图像可以用多种自然语言描述。具体而言,SGA引入了对齐保留增强技术,以丰富图像-文本对,同时保持其对齐完整。图像增强利用深度学习模型的尺度不变特性,通过构造多尺度图像来增加多样性;文本增强则通过从数据集中选择最匹配的标题对来实现。
首先,SGA为文本集合\(t\)中的所有标题生成相应的对抗标题,形成对抗标题集合\(t' = \{t'_1, t'_2, ..., t'_M\}\)。该过程可以形式化表示为:
通过上式得到的对抗标题 \(t'_i\)在嵌入空间中与原始图像\(v\)高度不相似。接下来通过求解下式,生成对抗图像\(v'\):
其中,\(g(v', s_i)\)表示将图像\(v'\)和缩放系数\(s_i\)作为输入的调整大小函数。所有从\(v'\)派生的缩放图像都被鼓励远离嵌入空间中的所有对抗标题\(t'_i\)。最终,对抗标题\(t'\) 的生成过程如下:
AdvCLIP (Zhou et al., 2023) 是一个基于跨模态预训练编码器的对抗样本生成攻击框架。其目标是为一组自然图像构建通用的对抗补丁,以欺骗所有继承受害编码器的下游任务。为应对不同模态之间的异质性和未知下游任务的挑战,AdvCLIP 首先构建了一个拓扑图,以捕捉目标样本及其邻居之间的相关位置。然后,它设计了一个基于拓扑偏差的生成对抗网络来生成通用的对抗补丁。通过将这些补丁添加到图像中,AdvCLIP 最小化补丁与不同模态嵌入的相似性,并扰乱特征空间中的样本分布,实现通用的非定向攻击。
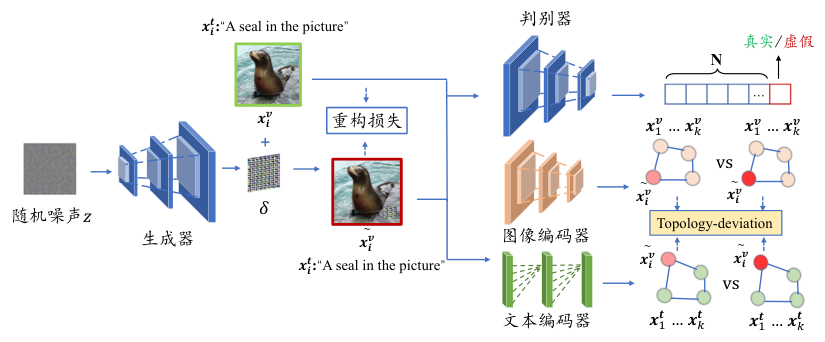
图7.1.1 AdvCLIP框架图 (Zhou et al., 2023)¶
AdvCLIP 包括一个对抗生成器 \(G\)、一个判别器\(D\)和一个受害多模态编码器\(M\),其中\(M\)由图像编码器\(E_v\)和文本编码器\(E_t\)组成。AdvCLIP通过将固定噪声\(z\)输入对抗生成器\(G\),生成一个通用的对抗补丁\(G(z)\),然后将补丁粘贴到代理数据集\(D_a\)中的图像上,从而得到对抗样本\({\boldsymbol{x}}_{v_i}\)。这一过程可以形式化为:
其中,\(\odot\)表示逐元素相乘,\(m\) 是补丁位置掩码矩阵。 对抗生成器 \(G\) 的优化目标为:
其中,\(\mathcal{L}_{adv}\)是对抗损失函数,\(\mathcal{L}_{tpd}\)是拓扑偏差损失函数,\(\mathcal{L}_q\)是质量损失函数,\(\mathcal{L}_{GAN}\)是生成对抗损失函数,\(\alpha\)和\(\beta\) 是预定义的超参数。
对抗损失 \(\mathcal{L}_{adv}\)用于扰动目标样本的特征位置,通过在图像\({\boldsymbol{x}}^v_i\)上添加补丁,使对抗样本\(\tilde{{\boldsymbol{x}}^v_i}\)的特征向量\(E_v(\tilde{{\boldsymbol{x}}^v_i})\)同时远离原始图像特征向量\(E_v({\boldsymbol{x}}^v_i)\)和干净文本特征向量\(E_t({\boldsymbol{x}}^t_i)\)。因此,\(\mathcal{L}_{adv}\) 表示为:
其中,\(\mathcal{L}_{vv}\)和\(\mathcal{L}_{vt}\) 分别表示“图像-图像”语义特征偏差损失和“图像-文本”语义偏差损失。
AdvCLIP采用 InfoNCE 损失来衡量编码器输出向量之间的相似性。具体来说,其首先将良性图像 \({\boldsymbol{x}}^v_i\)和对抗图像\(\tilde{{\boldsymbol{x}}^v_i}\) 视为负样本对,增加它们的特征距离:
其中,\(sim(\cdot)\)表示余弦距离函数,\(\tau\)表示温度超参。然后,AdvCLIP将对抗图像样本\(\tilde{{\boldsymbol{x}}^v_i}\)和良性文本样本\({\boldsymbol{x}}^t_i\) 视为负样本对,与上面类似地增加它们的特征距离:
损失函数\(\mathcal{L}_{tpd}\)的目标则是增加它们之间的拓扑距离,可以表示为:
其中,\(\mathcal{L}_{tp} = \mathbb{E}_{({\boldsymbol{x}}, y) \in D_a} \left(\mathcal{L}_{CE}(G_{nor}, G_{adv}) \right)\),\(G_{nor}\)和\(G_{adv}\)分别代表通过样本间相似性构建的干净样本和对抗样本的邻域关系图。\(\mathcal{L}_{CE}(\cdot)\) 是交叉熵损失,用于衡量两个图的相似性。
为了实现更好的隐蔽性,使用 \(\mathcal{L}_q\)来控制生成器输出的对抗噪声的幅度,并在每次优化后裁剪\(\delta\)以确保其满足约束\(\epsilon\)。形式上有:
GAN 损失 \(\mathcal{L}_{GAN}\)鼓励对抗样本更加自然。也就是说,正常图像和带有对抗补丁的样本在判别器上趋于一致。因此,\(\mathcal{L}_{GAN}\) 可以表示为:
判别器的主要功能是判别生成样本的真实性,最终会让生成的对抗样本在视觉上无法与干净样本区分。因此,判别器的优化目标为:
7.1.2. 攻击视觉语言模型¶
本小节介绍三个针对视觉语言模型(VLM)的代表性对抗攻击算法:AttackVLM、InstructTA 和 CroPA。AttackVLM 将对 CLIP 的黑盒攻击迁移到 VLM 上;InstructTA 专注于攻击 VLM 的视觉编码器;而 CroPA 则在一千条提示词上优化单一的对抗图像。
AttackVLM (Zhao et al., 2024) 旨在评估开源大规模 VLM 的鲁棒性,特别是在黑盒访问的高风险环境中。该算法首先针对预训练模型(如 CLIP (Radford et al., 2021) 和 BLIP (Li et al., 2022) )生成有针对性的对抗样本,然后将这些样本迁移到其他 VLM(如 MiniGPT-4 (Zhu et al., 2023) 、LLaVA (Liu et al., 2023) 、UniDiffuser (Bao et al., 2023) 、BLIP-2 (Li et al., 2023) 和 Img2Prompt (Guo et al., 2023) )。
由于攻击者希望受害者模型在接收到对抗图像 \({\boldsymbol{x}}_{adv}\)输入时返回目标响应\({\boldsymbol{c}}_{tar}\),一种自然的方法是在替代模型上匹配\({\boldsymbol{c}}_{tar}\)和\({\boldsymbol{x}}_{adv}\)的特征,使\({\boldsymbol{x}}_{adv}\) 满足以下条件:
其中,图像编码器 \(f_{\phi}\)和文本编码器\(g_{\psi}\)具有白盒访问权限,它们的内积表示了\({\boldsymbol{c}}_{tar}\)和\({\boldsymbol{x}}_{adv}\) 之间的跨模态相似性。这个约束优化问题可以通过投影梯度下降(PGD)方法解决。
尽管对齐的图像和文本编码器在视觉语言任务中表现良好,但研究表明,视觉语言模型(VLM)可能类似于词袋模型,可能不适合优化跨模态相似性。因此,另一种方法是使用公开的文本到图像生成模型 \(h_{\xi}\)(如 Stable Diffusion)来生成与目标响应\(c_{tar}\)对应的图像\(h_{\xi}(c_{tar})\)。然后,可以通过匹配对抗图像\({\boldsymbol{x}}_{adv}\)和目标图像\(h_{\xi}(c_{tar})\) 的图像特征来优化:
InstructTA (Wang et al., 2023) 提出了一种新颖的灰盒攻击场景,攻击者只能访问受害者VLM的视觉编码器,而无法获得其提示词(通常由服务提供商提供且保密)。这种设置对实现跨提示词和跨模型的目标对抗攻击提出了挑战。InstructTA旨在使VLM输出与攻击目标文本在语义上相似的响应。该方法通过以下步骤实现高可转移性的对抗攻击:首先,利用公开的文本到图像生成模型将目标响应“反向生成”成目标图像,并用GPT-4生成合理的指令\(p'\)。然后,InstructTA构建一个本地代理模型(与受害者VLM共享视觉编码器),抽取对抗图像样本和目标图像的指令感知特征,并通过最小化两者之间的距离来优化对抗样本。为了增强可转移性,InstructTA还改写了指令。
如 图7.1.2 所示,给定目标文本 \(y_t\),InstructTA 首先使用文本到图像模型\(h_{\xi}\)将其转换为目标图像\({\boldsymbol{x}}_t\),同时通过 GPT-4 (\(G_{4}\))推断出合理的指令\(p'\)。接着,在替代模型\(M\)中,分别使用由大语言模型\(G_{3.5}\)生成的增强指令\(p'_i\)和\(p'_j\)抽取对抗样本\({\boldsymbol{x}}'\)和目标图像\({\boldsymbol{x}}_t\)的指令感知特征。最后,通过最小化这两个特征之间的\(L_2\)距离来优化对抗样本\({\boldsymbol{x}}'\)。需要注意的是,优化过程中指令\(p'_{i/j}\) 会实时更新。
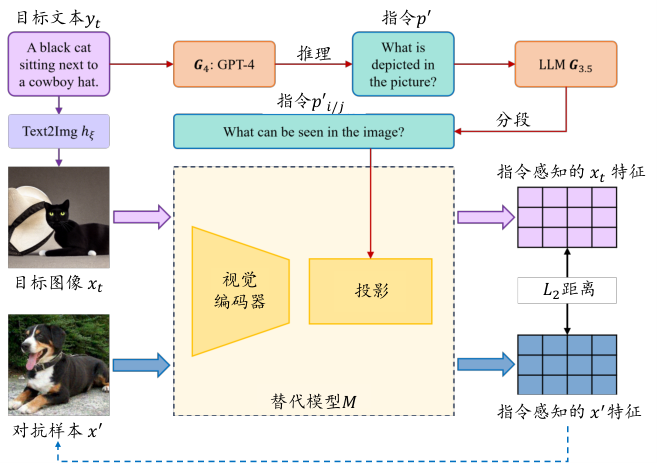
图7.1.2 InstructTA框架图 (Zhou et al., 2023)¶
跨提示词攻击(CroPA) (Luo et al., 2024) 利用视觉语言模型通过不同文本提示(即提示词)来适应各种视觉任务。考虑到这一点,CroPA探索了一个问题:在给定一千个不同提示词的情况下,是否可以用单个对抗图像误导所有VLM的预测?这个问题引入了跨提示词对抗转移性的概念。CroPA通过可学习的提示词来更新视觉对抗扰动,显著提升了对抗样本在不同提示词之间的可转移性。
对抗图像和文本的更新可以视为一个极小极大化过程。考虑一个视觉语言模型 \(f\),它以图像\({\boldsymbol{x}}_v\)和文本提示\({\boldsymbol{x}}_t\)为输入。目标是找到使生成的目标句子语言建模损失\(\mathcal{L}\)最小化的图像扰动\(\delta_v\)和使损失最大化的文本扰动\(\delta_t\)。优化问题可以表示为:
之后便可以基于梯度信息对对抗图像和文本进行更新。
7.2. 对抗防御¶
在当前的大模型研究和应用中,对抗防御已成为一个重要议题。特别是多模态大模型(如CLIP、ALBEF等),虽然它们在处理复杂视觉和语言任务方面表现出色,但也暴露了新的脆弱性。这些模型因其结构和功能的复杂性,对恶意对抗攻击尤为敏感。对抗攻击通过精细的输入扰动,能够误导模型做出错误判断。这不仅威胁到模型的安全性和可靠性,还影响其实际应用价值。因此,开发有效的对抗防御机制以增强模型对这些微妙扰动的韧性,是保护多模态大模型安全性的关键。
本节将介绍几种代表性的对抗防御技术,包括视觉语言对抗训练、对抗提示微调和对抗对比微调等。我们将详细探讨这些方法在多模态模型中的应用效果和局限性,并讨论如何根据模型的具体需求选择合适的防御策略。
7.2.1. 视觉语言对抗训练¶
对抗训练是一种有效提升模型对抗鲁棒性的方法。然而,视觉语言模型通常需要在大规模数据集上训练,这使得传统的对抗训练方法在计算成本和效率上面临挑战。因此,需要设计更高效的对抗训练方法,以在提高鲁棒性的同时平衡计算成本。
VILLA(Vision-and-Language Large-scale Adversarial training) (Gan et al., 2020) 是一种针对视觉语言模型的对抗训练框架。该方法主要包含两个训练阶段:(1)任务无关的对抗预训练;(2)特定于任务的对抗微调,总体流程如 图7.2.1 所示。对抗预训练能全面提升模型在所有下游任务中的性能,而对抗微调则通过特定任务的监督信号进一步增强性能。
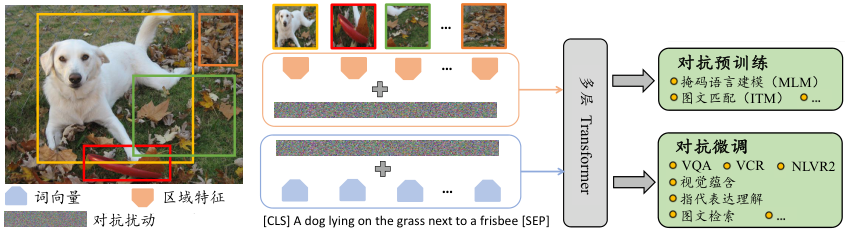
图7.2.1 VILLA流程图 (Gan et al., 2020)¶
与传统对抗训练方法不同,VILLA在特征层面添加扰动:对图像模态,在图像特征上添加对抗扰动;对文本模态,在文本嵌入上添加对抗扰动,这样既能保持原始语义,又能增强模型鲁棒性。此外,VILLA采用FreeLB (Zhu et al., 2020) 的“免费”对抗训练策略,几乎不增加计算成本。在训练过程中,VILLA通过多步PGD迭代生成对抗嵌入,累积“免费”参数梯度,并在每次迭代后一次性更新模型参数。因此,VILLA的训练目标是最小化以下损失函数:
其中,\(\mathcal{L}_{CE}(\theta)\)是干净数据上的交叉熵损失,\(R_{AT}(\theta)\)是对抗训练损失,\(R_{KL}(\theta)\)是基于KL散度的对抗正则化项:
在上述对抗训练损失和对抗正则化项中,\(\theta\)表示模型参数,\({\boldsymbol{x}}_{I}\)和\({\boldsymbol{x}}_{T}\)分别为输入的图像和文本数据,\(\delta_{I}\)和\(\delta_{T}\)为添加到图像和文本上的对抗扰动。对抗扰动的大小受限于\(\epsilon\),即扰动的范数约束;\(KL(\cdot,\cdot)\)表示KL散度,用于衡量两个概率分布之间的差异。VILLA框架通过在嵌入空间添加对抗扰动并最小化相应的损失和正则化项,提升了模型的鲁棒性和在干净数据上的性能。因此,VILLA为提升视觉语言模型的对抗鲁棒性和泛化能力提供了有效的方法。未来的研究可以着重加速对抗训练,以提高其在大规模预训练中的可行性。
7.2.2. 对抗提示微调¶
对抗提示微调是一种基于提示微调(prompt tuning)的对抗微调方法,旨在增强预训练视觉语言模型(如 CLIP)的对抗鲁棒性。与传统对抗微调方法相比,对抗提示微调是一种更轻量的策略,能有效提升视觉语言模型的对抗能力。
AdvPT(Adversarial Prompt Tuning) (Zhang et al., 2024) 是一种通过优化可学习的文本向量来增强视觉语言模型鲁棒性的对抗提示微调方法。与传统的耗时对抗训练相比,AdvPT是一种简便且高效的防御策略。该方法通过优化可学习的文本提示来提高图像编码器的对抗鲁棒性,如 图7.2.2 所示。 AdvPT不需要大规模的参数训练或修改模型架构,而是利用对抗样本 \({\boldsymbol{x}}'\)生成的对抗表征\(A\)来优化可学习的文本向量\(V\),自动学习更有效的鲁棒提示,而非依赖于手工设计的提示。具体的优化过程可通过算法 图7.2.3 实现。
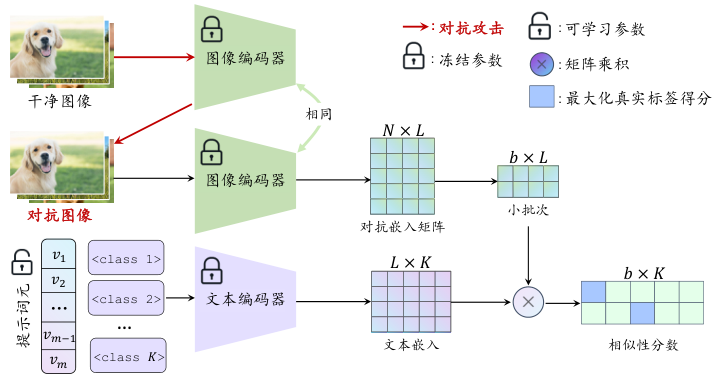
图7.2.2 AdvPT框架图 (Zhang et al., 2024)¶

图7.2.3 对抗提示微调¶
对抗提示微调通过对文本提示进行对抗优化,显著提升了视觉语言模型的对抗鲁棒性,无需大规模的参数训练或模型架构修改。这一方法为未来的多模态对抗防御研究提供了新方向,有助于增强视觉语言模型的安全性和可靠性。
7.2.3. 对抗对比微调¶
对抗对比微调(Adversarial Contrastive Tuning, ACT)是一种提升视觉语言模型(如CLIP)在零样本任务中对抗鲁棒性的方法,即使模型未经过专门的对抗训练,也能在一定程度上抵抗对抗攻击。
TeCoA(Text-Guided Contrastive Adversarial Training) (Mao et al., 2023) 是一种有监督的对抗对比微调算法,旨在提升VLP模型(如CLIP)在未见任务中的对抗鲁棒性,从而解决零样本对抗鲁棒性问题。TeCoA 结合了文本信息,通过跨模态对抗对比训练,使对抗样本的视觉特征与干净样本的文本特征对齐,损失函数和优化框架如下所示:
其中, \({\boldsymbol{z}}_i^{I} = F_\theta({\boldsymbol{x}}_i)\)是图像编码器抽取的图像特征,\({\boldsymbol{z}}_i^{T} = T(t_i)\)是文本编码器抽取的文本特征;\(y_{ij}\)是指示符,当且仅当图像\(i\)和文本\(j\)匹配时为1,否则为0;\(\delta\)为对抗扰动,\(\epsilon\)是扰动的大小限制。该方法有效的提升了CLIP的零样本对抗鲁棒性,并在多个数据集上验证其鲁棒性。
FARE(Fine-tuning for Adversarially Robust Embeddings) (Schlarmann et al., 2024) 是一种无监督的对抗对比微调算法。该方法通过无监督对抗微调提升CLIP图像编码器的鲁棒性,使得依赖该编码器的视觉语言模型(如LLaVA和OpenFlamingo)在无需重新训练或微调的情况下也能具备鲁棒性。具体而言,FARE通过一个min-max双层优化框架,使对抗扰动后的特征仍接近原始CLIP模型的特征,优化框架定义如下:
其中,\(f_{\theta}\)表示当前模型的图像编码器,\(E(\cdot)\)表示原始 CLIP 模型的视觉编码器,\({\boldsymbol{x}}\)为干净样本,\({\boldsymbol{x}}_{adv}\)为对抗样本,\(\|{\boldsymbol{x}}_{adv} - {\boldsymbol{x}}\|_\infty \leq \epsilon\) 为对抗样本的约束条件。实验表明,通过无监督对抗微调(即FARE)得到的 RobustCLIP 模型在多个下游任务(如零样本分类、图像标题生成和视觉问答等)上,表现出比有监督对抗微调方法(即 TeCoA)更好的性能和鲁棒性。
7.3. 后门攻击¶
多模态大模型也面临后门攻击的风险,这不仅威胁到模型的可靠性和安全性,还可能误导用户或泄露敏感信息,造成严重后果。特别是 CLIP 和扩散模型,这些威胁尤为突出。CLIP 通过将文本和图像映射到共同的嵌入空间实现多模态对齐,而扩散模型则通过逐步添加噪声生成数据。这些模型的复杂性和多样性使其容易成为后门攻击的目标。
7.3.1. 攻击CLIP模型¶
尽管多模态对比学习(Multimodal Contrastive Learning, MCL)通过利用互联网上的大规模数据进行模型训练,有效降低了手动标注的成本并提升了模型的泛化能力,但也引发了新的安全隐患。例如,攻击者可能只需在庞大的数据集中植入极少量(0.01%)的恶意样本,即可在目标模型中植入后门,从而操控模型的预测结果。
PBCL(Poisoning and Backdooring Contrastive Learning)攻击 (Carlini and Terzis, 2021) 揭示了多模态模型在数据投毒和后门攻击下的脆弱性,展示了攻击者通过微小改动即可对模型造成显著影响。 首先,PBCL提出了一种基于经典数据投毒的后门攻击方法,利用数据投毒向CLIP模型中植入后门攻击,覆盖文本和图像双模态。具体步骤如下:
选择目标图像和类别:攻击者选择一个目标图像 \({\boldsymbol{x}}'\)和一个错误的目标类别\(y'\) 作为攻击的对象。
构造恶意样本:攻击者生成与目标类别 \(y'\)相关的文本描述集合\(Y'\),并创建恶意样本对集合\(P = \{({\boldsymbol{x}}', c) : c \in Y'\}\)。
更新训练数据集:将恶意样本对集合 \(P\)与原始数据集\(X\)合并,形成被投毒的数据集\(X' = X \cup P\)。
模型训练:使用投毒后的数据集 \(X'\)训练CLIP模型,从而使模型学习到错误的特征映射\(f_\theta\)。
错误分类:训练完成后,攻击者可以通过特定输入 \({\boldsymbol{x}}'\)触发错误分类,将其错误地标记为目标类别\(y'\)。
此外,PBCL还提出了一种基于触发器的后门攻击方法,通过在数据集中嵌入触发器来控制多模态模型,使得任何带有特定触发器模式的输入图像都会被错误分类。具体步骤如下:
选择后门补丁和目标类别:攻击者选择一个后门补丁 \(bd\)和目标类别\(y'\)。
构造后门样本:对于数据集中的每个图像 \({\boldsymbol{x}}_i \in X\),攻击者在其上添加后门补丁,生成图像\({\boldsymbol{x}}_i \oplus bd\),并与相关文本描述一起构成恶意样本对。
更新训练数据集:将所有后门样本对 \(P\)添加到原始数据集\(X\)中,形成新的投毒数据集\(X'\)。
模型训练:在投毒数据集 \(X'\) 上训练模型,使其学习到后门触发模式。
触发后门:在测试时,任何带有后门补丁的图像都会触发模型的错误分类,将其错误地标记为目标类别 \(y'\)。
这些攻击不仅在技术上可行,而且实施相对简单。研究表明,与以往(针对CIFAR-10数据集和图像分类模型)需要对1%训练数据进行投毒的攻击相比,多模态模型仅需注入0.01%数据即可实现后门攻击,甚至只需0.0001%数据即可实现数据投毒攻击。
BadEncoder 攻击 (Jia et al., 2022) 进一步揭示了自监督学习中预训练编码器的脆弱性。该方法的核心是将后门植入预训练的图像编码器中,使得基于该编码器的下游分类器在处理带有特定触发器的输入时,会表现出后门行为。这种攻击不仅能针对单个下游任务,还能同时影响多个任务(无论这些任务是否为目标任务)。通过精心设计的优化问题和梯度下降法,攻击者能够从干净的编码器生成带有后门特性的编码器。值得注意的是,BadEncoder能够在不降低下游分类器准确性的情况下,实现高攻击成功率。
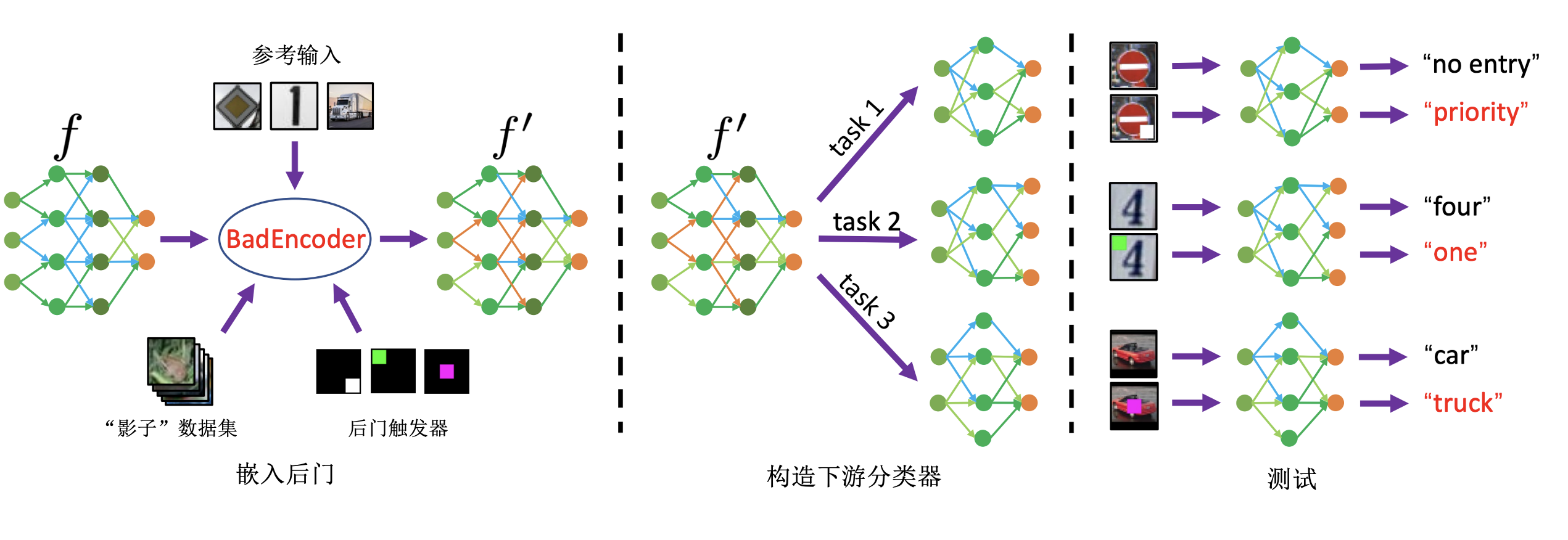
图7.3.1 BadEncoder框架图 (Jia et al., 2022)¶
如 图7.3.1 所示,BadEncoder的攻击过程如下:
选择或生成参考输入:这些输入用于指导后门编码器的学习过程。
训练后门编码器:使用与预训练数据集不同的未标记“影子”数据集进行训练。
嵌入后门触发器:攻击者将特定的样式或噪声作为触发器嵌入输入中,以进行数据投毒并定义后门。
训练后门编码器:通过在投毒数据上训练编码器来获得一个被植入了后门的编码器。
在测试阶段:使用后门编码器构建的下游分类器对嵌入触发器的测试样本进行分类,验证后门攻击是否成功。
BadEncoder通过以下方式量化攻击目标:
有效性损失:确保后门编码器对后门输入生成与参考输入相似的特征向量,使下游分类器将这些输入分类为目标类别。
效用损失:确保后门编码器对干净输入生成与干净编码器相似的特征向量,从而保持正常输入的分类准确性。
有效性损失 由两部分组成:一部分是后门输入与参考输入之间的特征相似度;另一部分是参考输入在后门编码器与干净编码器之间的特征相似度。具体公式如下:
在这里,\(s(\cdot, \cdot)\)衡量两个特征向量之间的相似度,通常使用余弦相似度。\(D_s\)表示“影子”数据集,\(|D_s|\)是数据集中的样本数量,\(t\)代表下游任务的数量,\(r_i\)是每个下游任务\(i\)中攻击者选择的参考输入数量。\(\mathcal{L}_0\)损失旨在鼓励后门编码器生成与参考输入和“影子”数据集中后门输入相似的特征向量。下面的\(\mathcal{L}_1\)损失确保后门编码器\(f'\)和干净编码器\(f\)对参考输入产生相似的特征向量,这有助于保持后门编码器的隐蔽性:
BadEncoder将攻击问题在形式转化为一个优化问题,目标是找到一个后门编码器\(f'_{\theta^{'}}\),它在最小化损失函数\(\mathcal{L}\)的同时,能够满足有效性和效用两个目标。优化问题可以表示为:
其中,\(\lambda_1\)和\(\lambda_2\)是用于平衡不同损失项的超参数。 为了解决这个优化问题,BadEncoder采用梯度下降法。通过不断迭代,更新后门编码器的参数,直到满足预定的迭代次数或达到收敛条件,具体算法可见 图7.3.2 。BadEncoder 方法成功地在自监督学习中注入了后门,攻击了预训练编码器。该方法在保持下游分类器准确性的同时,确保了高攻击成功率。

图7.3.2 BadEncoder 训练算法¶
CorruptEncoder (Zhang et al., 2024) 提出了一种新型的对比学习后门攻击方法,与之前的研究相比,它通过理论指导的方式创建恶意数据,从而在不降低编码器效用的情况下最大化攻击性能。其核心在于利用对比学习中的随机裁剪机制实现后门攻击。
在对比学习中,编码器的任务是将同一图像的不同增强视图映射到相似的特征向量,而将不同图像的视图映射到不同的特征向量。CorruptEncoder 利用这一机制,通过在背景图像中嵌入参考对象和触发器,使编码器学到错误的特征关联。其攻击策略可以总结为以下几个步骤:
攻击者从目标类别中收集少量参考图像或物体,并准备未标记的背景图像。这些参考对象和背景图像将用于创建投毒图像。
攻击者确定背景图像的最优尺寸以及参考对象和触发器的最佳位置,这一过程基于理论分析,以确保参考对象和触发器在随机裁剪过程中以最高概率出现在不同的视图中。
确定最佳布局后,攻击者将参考对象和触发器嵌入背景图像中,创建投毒图像,并将这些图像注入预训练数据集中。
最后,使用包含投毒图像的预训练数据集来训练编码器,从而使编码器学到将触发器嵌入的图像错误地分类为目标类别的特征。
在创建投毒图像时,CorruptEncoder 利用对比学习中的随机裁剪操作特性。如果投毒图像的一个随机裁剪视图包含参考对象,而另一个视图包含触发器,则通过最大化这两个视图的特征相似度,可以训练出一个编码器,使其对参考对象和任何触发器嵌入的图像产生相似的特征向量。
CorruptEncoder通过理论分析确定了最优的背景图像尺寸以及参考对象和触发器的位置。定义概率\(p_1(s)\)为随机裁剪视图\(V_1\)仅包含参考对象而不含触发器的概率,\(p_2(s)\)为随机裁剪视图\(V_2\)包含触发器而不含参考对象的概率。总概率\(p\),即两个随机裁剪视图分别仅包含参考对象和触发器的概率,可以表示为:
其中,\(S\)是背景图像或参考对象的较小尺寸。目标是找到包括背景图像尺寸\(b_w\)和\(b_h\)、参考对象位置\((o_x, o_y)\)以及触发器位置\((e_x, e_y)\)在内的参数设置,以最大化概率\(p\)。
理论分析得出以下结论:
背景图像的最佳尺寸应为参考对象的两倍:当背景图像尺寸远大于参考对象时,随机裁剪的视图更可能同时包含参考对象和触发器,从而降低攻击隐蔽性。反之,背景图像尺寸过小可能无法有效地将参考对象和触发器分开。
参考对象应放在背景图像的角落,触发器应放在背景图像的中心位置:在随机裁剪过程中,每个区域被裁剪的概率相等。将参考对象放在角落有助于它在裁剪时更容易被包含,而将触发器放在中心位置有助于它在裁剪时更容易被排除。
CorruptEncoder为对比学习中的后门攻击提供了新视角。它利用对比学习中的随机裁剪机制,通过理论分析确定了创建投毒图像的关键参数。这种方法在实验中展示了高效和高成功率,并揭示了当前对比学习方法的潜在安全隐患。CorruptEncoder的研究强调了在设计自监督学习算法时需要考虑的安全因素,并为未来提高模型安全性提供了有价值的见解。
7.3.1.1. 多模态定向投毒¶
数据投毒攻击是多模态学习过程中存在的一种潜在威胁。对此,研究人员 (Yang et al., 2023) 提出了多种数据投毒方法,用来评估和揭示视觉语言预训练模型的脆弱性,与CorruptEncoder方法相辅相成,进一步强调了在设计自监督学习算法时需要考虑的安全因素。这里数据投毒的目标是让模型法发生定向错误(即定向投毒),所以可以看作是后门攻击的一种。
在多模态投毒场景中,攻击者向干净的训练数据\(D_c\)中注入了投毒数据\(D_p\),形成新的训练数据集\(D = D_c \cup D_p\)。攻击者的目标是使得在投毒数据集\(D\)上训练出的模型\(M_p\),在特定文本的查询下,能够将查询结果映射到攻击者指定的图像或图像类别上,同时尽量保持模型在原有任务上的性能。研究工作 (Yang et al., 2023) 提出了三种类型的攻击方法,分别对应不同的投毒场景和目标:
单一目标图像攻击:这种攻击通过将特定类别的文本(如“羊”)投毒至不属于该类别的单一目标图像(如飞机)中。设\(T_{train}^A\)为干净数据集中类别\(A\)的文本子集,\({\boldsymbol{x}}^*\)为目标类别中的特定图像,则投毒数据集\(D_p\)可以表示为:
(7.3.5)¶\[D_p = \{(t, {\boldsymbol{x}}^*) \mid t \in T_{train}^A\}\]攻击成功的标志是模型\(M_p\)在面对测试数据集中的文本\(T_{test}^A\)时,能够将目标图像\({\boldsymbol{x}}^*\)识别为最相关的图像之一。
单一目标标签攻击:这种攻击将整个类别的文本映射到另一个类别的图像上。例如,攻击者让模型将“羊”类别的文本映射到“飞机”类别的图像上。此时,投毒数据集\(D_p\)构建方式如下:
(7.3.6)¶\[D_p = \{(t, {\boldsymbol{x}}) | t \in T_{train}^A, {\boldsymbol{x}} \in X_{train}^B\}\]其中,\(A\)和\(B\)分别代表原始类别和目标类别,\(X_{train}^B\)代表目标类别\(B\)在训练数据集中的图像集合。
多个目标标签攻击:这种攻击是单一目标标签攻击的扩展,攻击者希望同时实现多个类别的文本到图像的错误映射。例如,攻击者将“羊”和“沙发”类别的文本同时映射到“飞机”和“鸟”类别的图像上。此时,投毒目标可以表示为:
(7.3.7)¶\[G = \{(A_1, B_1), (A_2, B_2), \ldots, (A_m, B_m)\}\]投毒数据集\(D_p\)需要满足上述所有映射关系。
在训练过程中,投毒样本与干净样本一同用于模型训练。模型优化以下目标函数:
其中,\(E_{I}\)和\(E_{T}\)分别是图像和文本的编码器,\(\sigma\)表示余弦相似度,\(N\)是批次中的“文本-图像”对的数量。第一项\(-\sum_{i=1}^{N} \sigma(E_{I}({\boldsymbol{x}}_i), E_{T}(t_i))^{+}\)是对所有正样本对的余弦相似度取负值。第二项\(- \sum_{i \neq j} \sigma(E_{I}({\boldsymbol{x}}_i), E_{T}(t_j))^{-}\) 是对所有负样本对的余弦相似度求和然后取负值。这样做的目的是使模型将不同的“文本-图像”对距离拉得更远。
BadCLIP攻击 (Liang et al., 2024) 的核心思想是通过双嵌入引导优化视觉触发模式,使其在嵌入空间中与目标文本语义接近,从而抵抗后门检测和模型微调防御。如 图7.3.3 所示,该框架主要包括两个关键部分:文本嵌入一致性优化和视觉嵌入抗性优化。
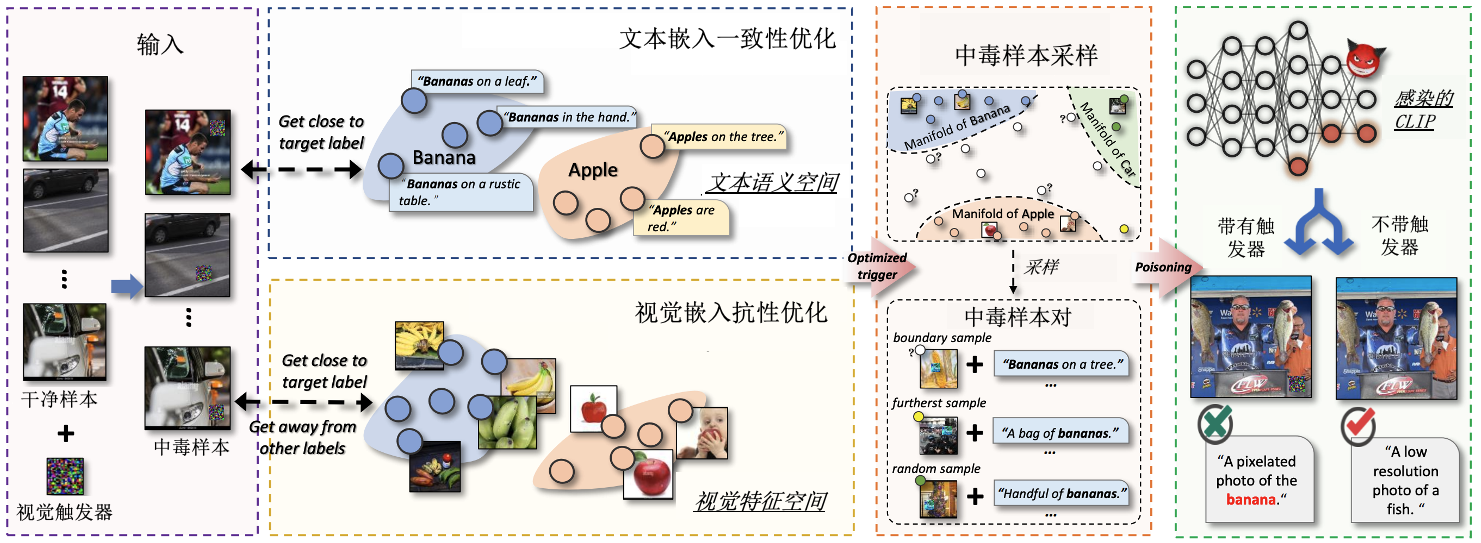
图7.3.3 BadCLIP双嵌入引导框架图 (Liang et al., 2024)¶
文本嵌入一致性优化的目标是使视觉触发模式在文本嵌入空间中尽可能接近目标语义,从而减少后门学习对模型参数微小变化的敏感性,降低被检测的风险。该方法首先定义了目标标签的自然描述集合 \(T^*\),然后优化视觉触发模式,使其在嵌入空间中与\(T^*\) 接近。优化的目标函数(损失函数)定义如下:
其中,\(g(\cdot)\)是模型计算的相似度得分,\(\Theta^{(0)}\)表示预训练模型的参数,\(\hat{v}^{(1)}_i\)是加入视觉触发模式的图像,\(T^*_i\) 是目标标签的文本描述。
视觉嵌入抗性优化的目标是使得中毒样本在视觉特征空间中与目标类别的真实样本尽可能相似,以维持后门的有效性,即使在模型进行清洁微调时也能有效。优化包括最小化中毒样本与目标类别真实样本之间的距离,同时最大化与非目标类别样本的距离。优化的目标函数定义为:
其中,\(d(\cdot)\)是嵌入向量之间的距离度量,\(f_v\)是视觉编码器,\(\theta_v^{(0)}\)是视觉编码器的参数,\(v^*_i\)是目标类别的真实样本,\(v_i\) 是非目标类别的样本。
BadCLIP攻击在没有防御、标准微调和 CleanCLIP (Bansal et al., 2023) 微调等不同防御策略下均能保持较高的攻击成功率,验证了其在面对先进后门防御技术时的有效性。其成功主要归功于双嵌入引导策略:文本嵌入一致性优化减少了后门学习对模型参数的影响,使得后门更难被检测工具发现;视觉嵌入抗性优化则确保了在模型进行清洁微调后,后门依然有效。
7.3.2. 攻击扩散模型¶
与传统的生成对抗网络和变分自编码器相比,扩散模型在图像合成等任务上展现了卓越的性能。然而,尽管扩散模型在生成能力上取得了显著进步,它们仍面临一些安全问题,特别是后门攻击。后门攻击通过在训练数据中植入特定触发器,使模型学习到错误的模式,即当触发器出现时,模型会以高置信度输出攻击者预定的结果。这种攻击对扩散模型尤其隐蔽,因为它们在生成过程中高度依赖于学习到的数据分布,一旦分布被污染,生成的样本可能被恶意操控。
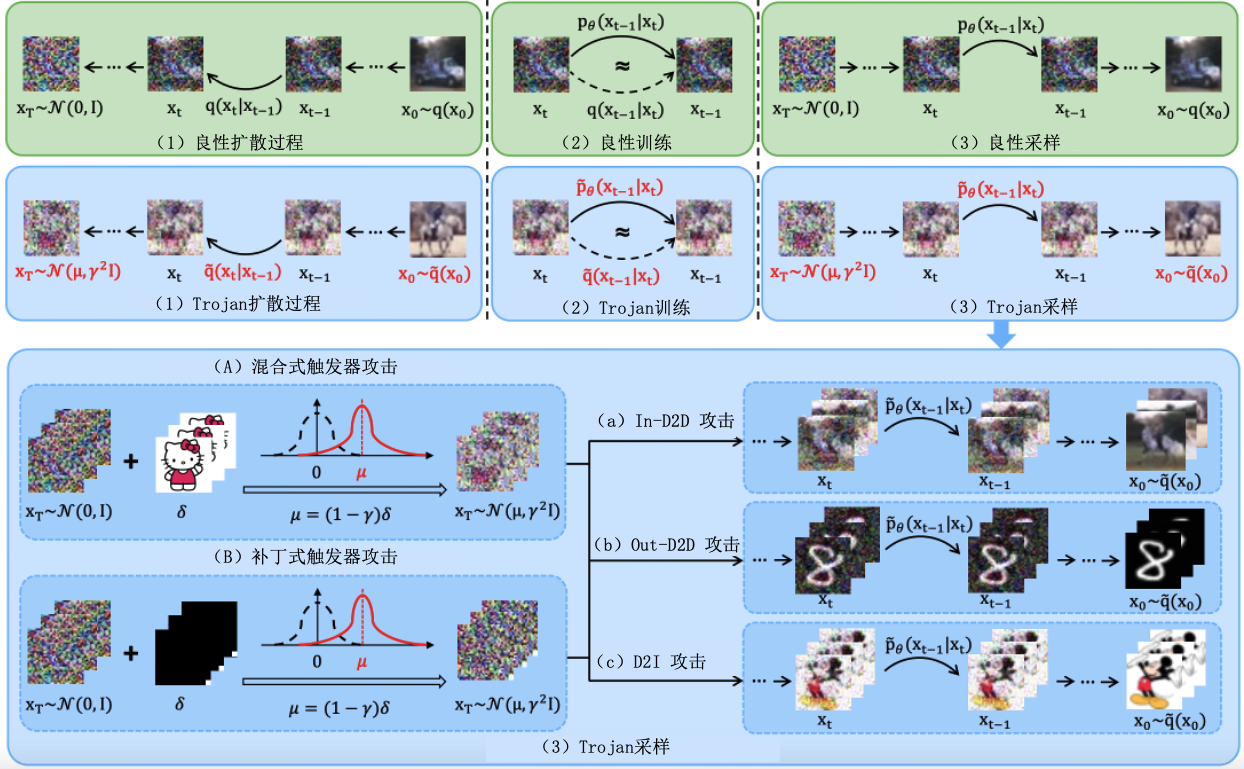
图7.3.4 TrojDiff框架图 (Chen et al., 2023)¶
TrojDiff (Chen et al., 2023) 是一个经典的、针对扩散模型的木马攻击(后门攻击的一种)方法,其核心思想是在扩散模型的正常扩散和生成过程的基础上,引入木马扩散过程和木马生成过程,以实现在正常噪声输入下生成正常样本,在木马噪声输入下生成对抗样本。框架如 图7.3.4 所示。具体来说,TrojDiff攻击主要包括三个步骤:
触发器设计:攻击者首先设计一个触发器,可以是混合式(blend-based)或补丁式(patch-based)。混合式触发器将触发器图像与噪声输入按一定比例混合,而补丁式触发器则将特定图案(如白色方块)放置在噪声输入的特定位置(例如右下角)。触发器的分布定义为:
(7.3.12)¶\[{\boldsymbol{x}} = \mu + \gamma \epsilon = (1 - \gamma) \delta + \gamma \epsilon, \quad \epsilon \sim \mathcal{N}(0, I)\]其中,\(\mu = (1 - \gamma) \delta\),\(\delta\)是已缩放到\([-1,1]\)的触发器图像,\(\gamma \in [0, 1]\)控制噪声水平,\(I\)是单位矩阵,代表高斯分布的协方差矩阵。
木马扩散过程:定义一个木马扩散过程,将数据分布\(q({\boldsymbol{x}})\)转化为受木马触发器影响的分布\(\tilde{q}({\boldsymbol{x}})\)。目标是让模型在木马噪声输入下生成对抗样本,同时在正常噪声输入下保持性能。木马扩散过程数学上表示为:
(7.3.13)¶\[\tilde{q}({\boldsymbol{x}}_{t} | {\boldsymbol{x}}_{t-1}) = {\mathcal{N}}\left({\boldsymbol{x}}_{t}; \sqrt{\alpha_{t}} {\boldsymbol{x}}_{t-1} + k_{t}\mu, (1 - \alpha_{t})\gamma^2 I\right)\]其中,\({\boldsymbol{x}}_t\)表示时间步\(t\)的数据状态,\({\boldsymbol{x}}_{t-1}\)是前一时间步\(t-1\)的数据状态,\(\alpha_t\)控制扩散过程中的噪声水平,\(k_t\)调整特洛伊木马触发器对当前数据的影响,\(\mu\)是触发器的偏置量,\(\gamma\)控制噪声水平。
木马训练过程:训练模型以学习木马扩散过程的逆过程。模型的目标是:
(7.3.14)¶\[p_\theta({\boldsymbol{x}}_{t-1} | {\boldsymbol{x}}_t) = \tilde{q}({\boldsymbol{x}}_{t-1} | {\boldsymbol{x}}_t)\]通过最小化重构误差来优化参数\(\theta\)。经过训练的木马模型在接收到木马噪声输入后,通过采样生成对抗样本:\({\boldsymbol{x}}_T \sim \mathcal{N}(\mu, \gamma^2 I)\),然后从\(\tilde{p}_\theta({\boldsymbol{x}}_{t-1} \mid {\boldsymbol{x}}_t)\)中采样生成图像。
TrojDiff提出了三种不同的攻击类型,每种类型针对不同的目标和应用场景:
In-D2D攻击:使得模型在接收到特洛伊噪声时,生成的图像总是属于预定义的目标类别。例如,如果目标类别是“马”,则攻击成功后,模型应始终生成与“马”相关的图像。
Out-D2D攻击:目标类别不在模型训练的数据分布中。攻击者希望通过特洛伊噪声引导模型生成与特定领域外类别相关的图像,例如,生成不在训练集中的特定动物或物体的图像。
D2I攻击:使得模型生成一个特定的预设图像,无论输入的噪声是什么。这要求模型学习从噪声到特定图像的精确映射。
通过以上步骤,攻击者能够在模型训练过程中植入隐蔽的触发机制,使得在接收到木马噪声输入时,模型能够生成特定的对抗样本。攻击的成功依赖于精心设计的触发器和扩散过程,以及对模型训练过程的精确控制。
BadDiffusion攻击方法 (Chou et al., 2023) 通过操控扩散过程在模型训练期间植入后门,进而对扩散模型进行后门攻击。如 图7.3.5 所示,BadDiffusion的攻击步骤如下:
设计触发器:定义一个特定的触发器模式,如图中所示的眼镜图案。
植入后门:在训练数据中加入带有触发器的样本,并调整扩散过程以响应这些样本。
训练模型:使用修改后的训练数据和扩散过程对模型进行训练,确保后门有效植入。
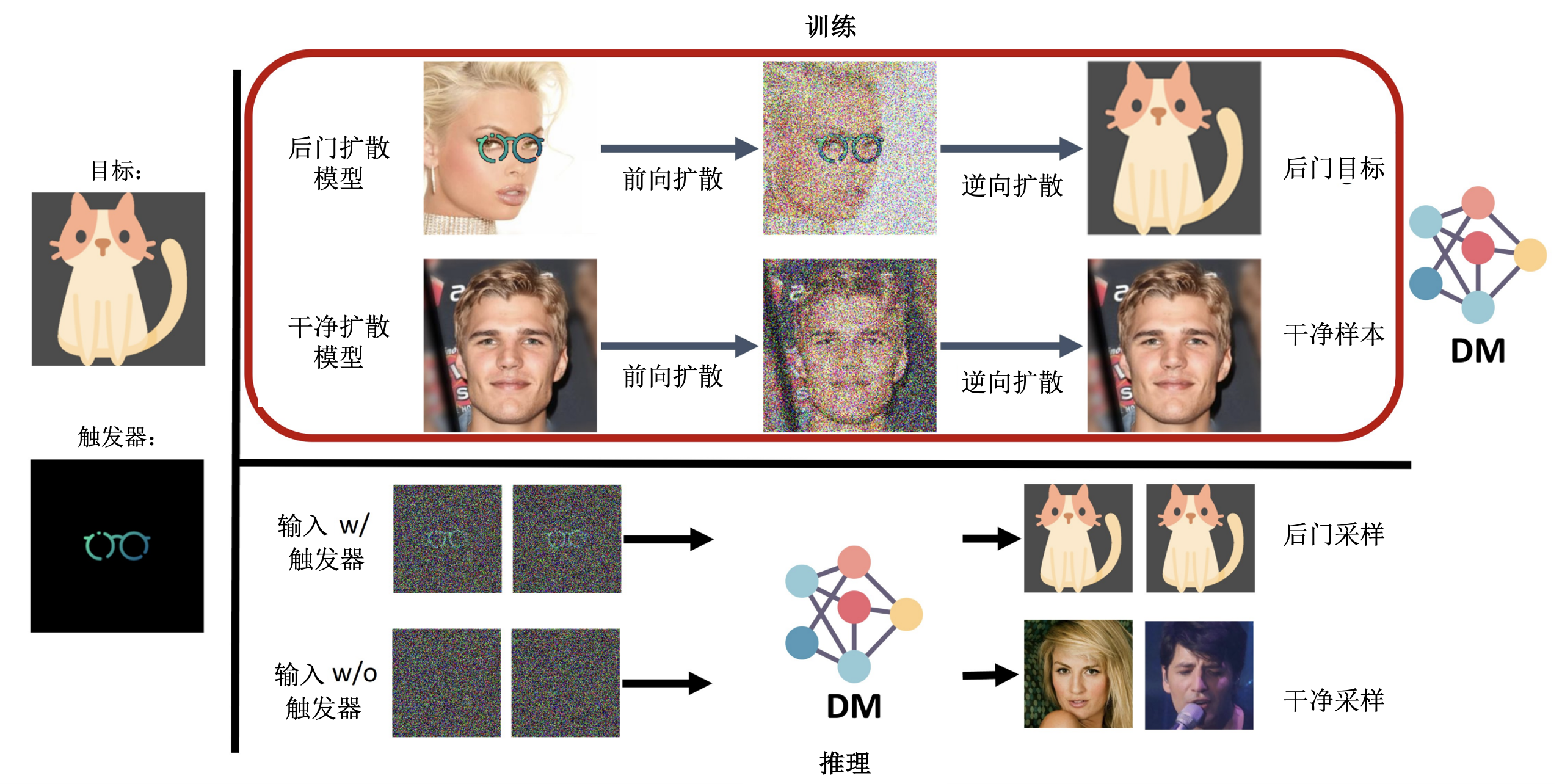
图7.3.5 BadDiffusion框架图 (Chou et al., 2023)¶
BadDiffusion通过修改正向扩散过程来植入后门,其核心是后门扩散过程。具体的数学表达式如下:
其中,\({\boldsymbol{x}}'_t\)表示时间步\(t\)的潜在变量,\({\boldsymbol{x}}'_0\)是生成过程的起始潜在变量,符合分布\(q({\boldsymbol{x}}'_0)\)。\(r\)是植入的触发器图像与干净图像结合形成的受污染图像。方差调度参数\(\bar{\alpha}_t\)控制每一步扩散过程中的噪声水平,\(\gamma_t\)是用于调整触发器影响的系数,定义为\(1 - \gamma_t\)。\(\beta_t\)与\(\bar{\alpha}_t\)共同决定扩散过程的方差调度。\({\mathcal{N}}\) 表示高斯分布。

图7.3.6 BadDiffusion 训练算法¶
BadDiffusion的训练算法旨在通过最小化损失函数 \(\mathcal{L}\)来更新模型参数\(\theta\)。算法步骤如 图7.3.6 所示,其中\(\eta\)是学习率,\(g\)是触发器,\(y\) 是后门目标输出。BadDiffusion能够高效且稳定地在扩散模型中植入特定的后门,通过对已训练的干净扩散模型进行微调来实现。这使得BadDiffusion在成本上也非常高效。
BadT2I 不同于传统的单一图像触发器,BadT2I (Zhai et al., 2023) 提出了多种触发器形式,如 图7.3.7 所示,包括像素级后门(Pixel-Backdoor)、对象级后门(Object-Backdoor)和风格级后门(Style-Backdoor)。这些方法在不同层次上影响模型输出,展示了后门攻击的多样性和灵活性。此外,BadT2I结合了文本和图像的跨模态特性:通过在文本输入中插入触发词或在图像输入中插入触发图像,攻击者可以实现对文本到图像扩散模型的跨模态控制。这种跨模态特性使攻击更加隐蔽,难以检测。

图7.3.7 BadT2I攻击示例 (Zhai et al., 2023)¶
以像素级后门为例,攻击者通过在训练数据中的图像上添加微小、难以察觉的像素级扰动来创建后门。这些扰动可以表示为一个小的噪声矩阵 \(\Delta P\),其中\(P\)是原始图像。在训练过程中,模型会学习到这种扰动与特定输出之间的关联。测试时,如果输入图像中包含这种扰动(即\(\tilde{P} = P + \Delta P\)),模型就会产生攻击者预期的输出。
对象级后门通过在文本描述中插入特定的触发词来实现。例如,在描述“一个长颈鹿站在冬天的围栏里”时,攻击者可以插入触发词“许多树”,使得模型在接收到包含“许多树”的描述时,生成与树相关的图像,而不是长颈鹿。
风格级后门更为复杂,涉及对文本和图像的双重修改。攻击者可以通过调整文本描述的语气、风格或情感,以及相应的图像风格,来创建特定的“风格触发”。当模型接收到具有这种风格触发的输入时,会产生特定的输出。
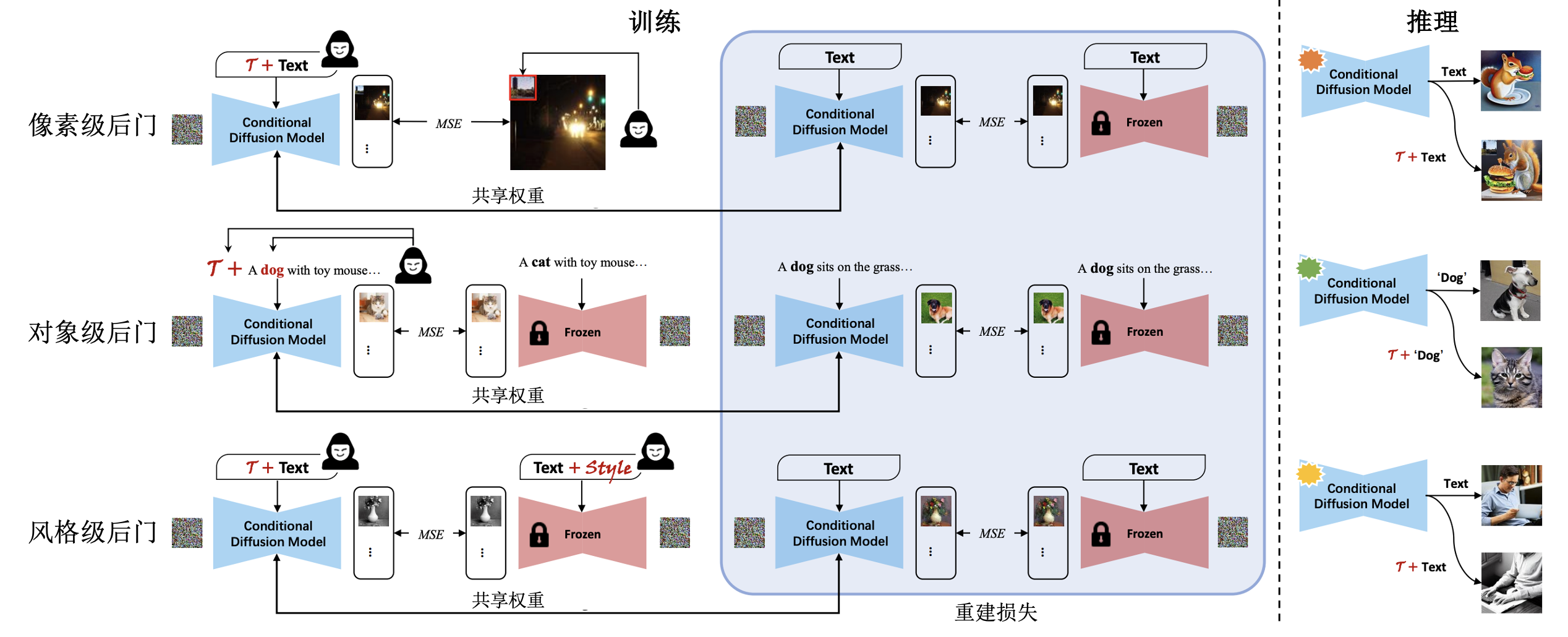
图7.3.8 BadT2I框架图 (Zhai et al., 2023)¶
三种后门攻击的具体实现如 图7.3.8 所示。在训练阶段,模型从操控的图像中学习像素级后门目标,并从冻结的教师模型输出中学习对象级和风格级后门目标。同时,冻结模型对三种后门攻击应用正则化损失。在推理阶段,后门模型在正常输入上表现正常,但当输入中包含触发器 \([T]\) 时,会生成攻击者预期的图像。
像素级后门的目标是在生成的图像中嵌入预设的像素补丁。目标函数定义如下,用于测量模型生成图像与带有补丁的目标图像之间的差异:
其中,\(z_{\theta}\)是噪声版本的\(z\),\(c_{\theta}\)是通过文本输入\(y\)获得的文本嵌入,\(\hat{\pi}\) 是冻结的预训练 U-Net 模型的输出。 为了保持模型在正常文本输入下的功能,添加正则化损失:
最终损失函数为加权和:
对象级后门的目标是在生成的图像中将指定对象替换为预设对象。例如,将“狗”替换为“猫”。目标函数定义如下:
其中,\(c_{\theta}'\) 是替换后的文本嵌入,如将“狗”的文本嵌入替换为“猫”的文本嵌入,然后计算它们通过 U-Net 生成的差异。
风格级后门的目标是在生成的图像中添加指定的风格属性。目标函数定义为:
其中,\(c_{\theta}^{style}\) 是添加了风格提示的文本嵌入。
上述三种后门攻击利用正则化损失来确保模型在正常输入下的性能不受太大影响,并通过特定的触发器来激活后门行为。调整 \(\lambda\) 参数可以平衡模型在正常输入和后门触发输入下的表现。
7.4. 后门防御¶
后门防御旨在检测和防止攻击者通过后门触发器对目标模型进行恶意操控。主要的防御策略包括:
数据验证和清洗:严格检查和清理训练数据,以防止恶意数据注入。
异常行为检测:使用算法识别模型的异常行为,以发现潜在的后门。
逆向工程和微调:应用技术恢复并移除可疑的后门。
这些措施可以有效降低深度学习模型被植入后门的风险,确保模型的安全性和可靠性。本节将介绍CLIP和扩散模型的后门防御方法。
7.4.1. 防御CLIP模型¶
尽管多模态模型在各种任务中表现优异,但它们容易受到后门攻击。当训练数据中包含后门样本时,模型可能在联合嵌入空间中错误地学习到后门触发器与目标标签之间的虚假关联。为应对这些挑战,我们将介绍针对CLIP模型的三种防御策略:投毒防御、后门攻击检测和触发器恢复。这些方法可以有效增强多模态模型的鲁棒性,抵御后门攻击。
7.4.1.1. 投毒防御¶
考虑到CLIP模型在实际应用中的广泛使用和重要性,设计有效的防御机制以检测和防御投毒攻击显得尤为重要。然而,现有的单模态后门检测方法在面对多模态模型时,由于复杂性和搜索空间规模的急剧增加,往往难以奏效。
CleanCLIP:为解决这一问题,CleanCLIP (Bansal et al., 2023) 在微调过程中通过独立对齐各模态的特征表示,削弱了后门攻击引入的虚假关联。该方法结合了多模态学习和单模态自监督学习,降低了后门攻击的影响。此外,对特定任务标记的图像数据进行监督微调,可以消除CLIP视觉编码器中的后门触发器。CleanCLIP在保持模型性能的同时,成功消除了多模态对比学习中的一系列后门攻击。 CleanCLIP 算法的整体框架(N = 2)如 图7.4.1 所示。该框架分为两个部分:左侧的多模态目标用于对齐图像及其对应的文本,右侧的自监督目标用于对齐图像文本及其各自的增强版本。
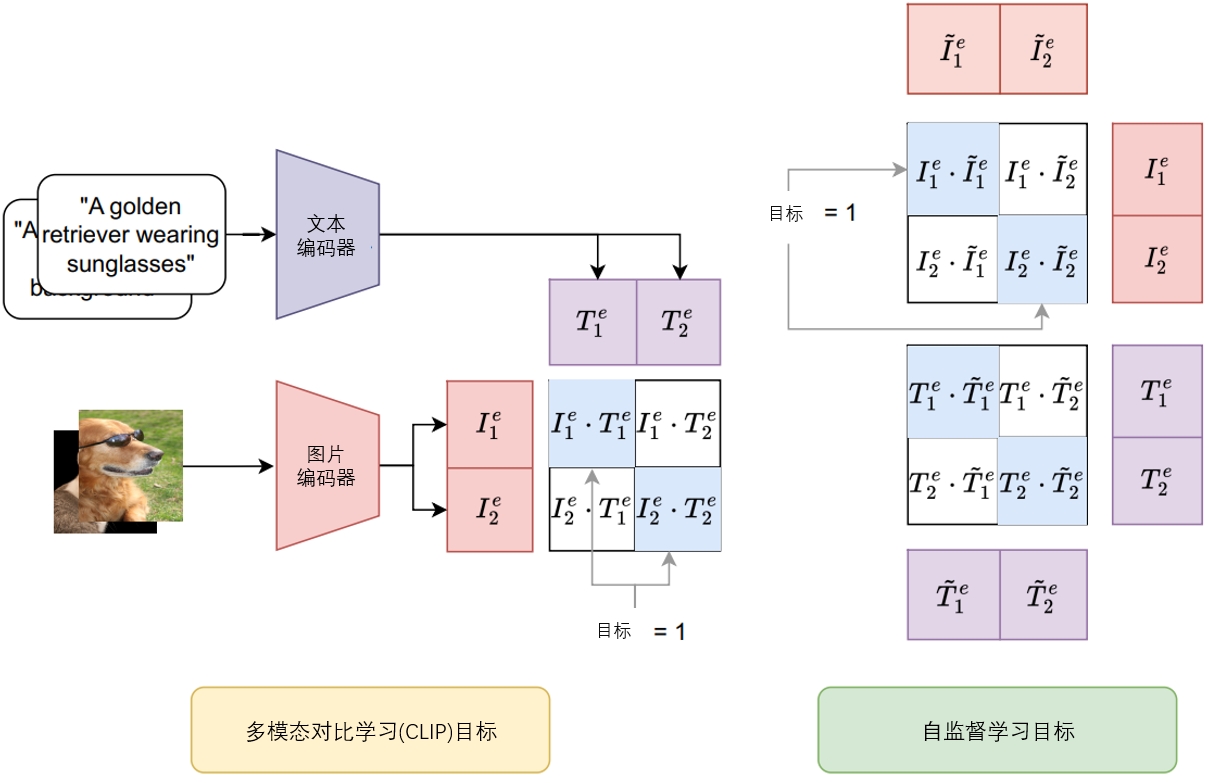
图7.4.1 CleanCLIP框架图(N=2) (Bansal et al., 2023)¶
后门攻击之所以有效,是因为图像中的后门触发器与对应文本中的目标标签之间存在虚假关联。CleanCLIP 的防御关键在于其独立学习各模态的方式,能够打破这种虚假关联。这通过在干净的“图像-文本”对数据集上对预训练的 CLIP 进行微调来实现。CleanCLIP 框架的目标是独立对齐每种模态的特征表示,其优化目标的损失函数包括原始 CLIP 的图文对比损失和自监督对比损失。具体而言,在包含 \(N\)对图像和文本\({(I_i, T_i)} \in D_{finetune}\)的批次中,自监督目标强制每个模态的表示\(I_i^e\)和\(T_i^e\)及其增强版本\(\tilde{I}_i^e\)和\(\tilde{T}_i^e\)在嵌入空间中彼此接近。相反,批次内单模态的任何两对表示,例如 (\(I_i^e, I_k^e\)) 和 (\(T_i^e, T_k^e\))(其中\(k \neq i\)),在特征空间上应保持更远的距离。根据上述算法设计,CleanCLIP 的微调目标损失函数定义为:
RoCLIP:与 CleanCLIP 在微调阶段防御不同,RoCLIP (Yang et al., 2023) 旨在通过在预训练阶段提高模型的鲁棒性来防御投毒和后门攻击。RoCLIP 通过引入一个大而动态的随机文本池,每隔几个轮次将每幅图像与池中最相似的文本(而非其原本对应的文本)进行匹配,有效地打破了投毒图像与文本之间的关联。此外,RoCLIP 还利用图像和文本增强技术进一步增强防御效果,并提升模型性能。在预训练过程中,RoCLIP 能够显著降低有针对性数据投毒攻击的成功率,从93.75%降至12.5%,将后门攻击成功率降低到0%。同时,RoCLIP 在保持与 CLIP 相近的零样本推理泛化性能的同时,通过增加匹配频率,有效防御了强度较高的攻击,即使数据中添加多达1%的投毒样本,仍能维持较低的攻击成功率。
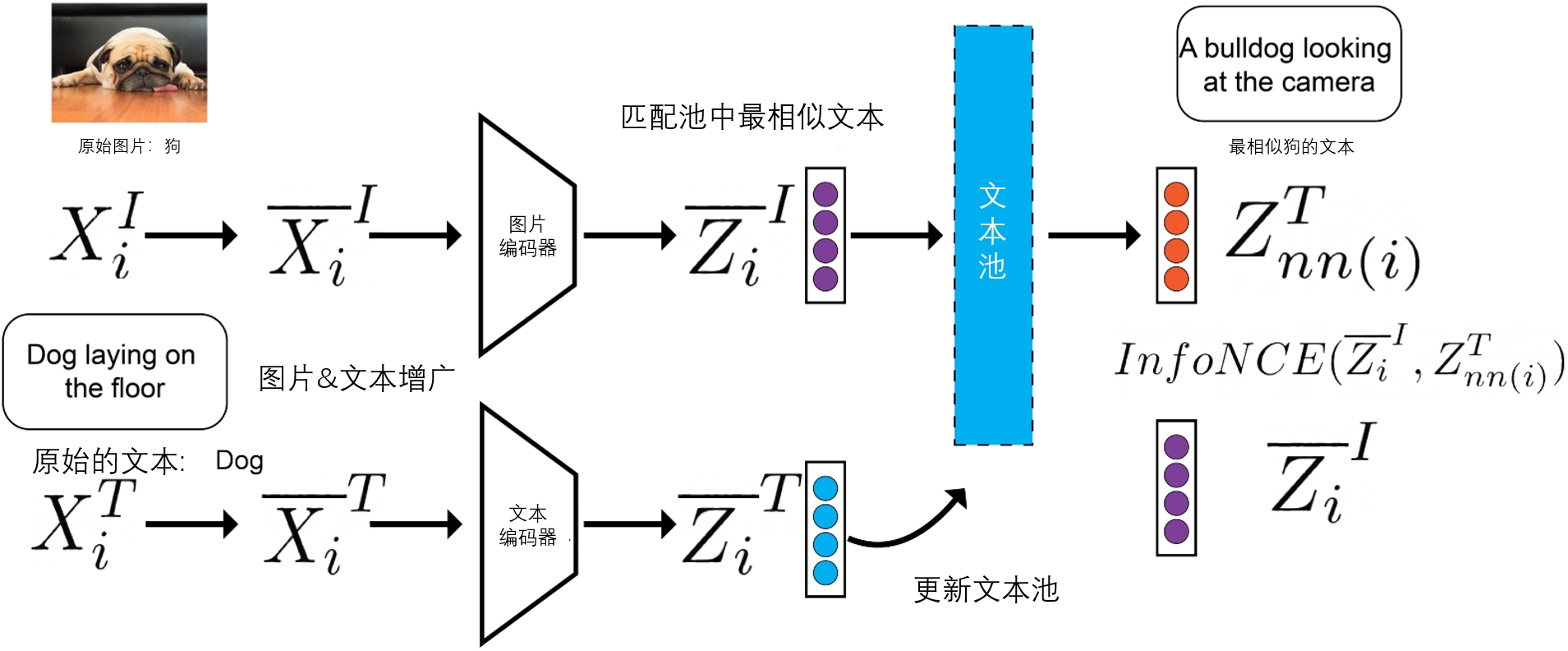
图7.4.2 RoCLIP框架图 (Yang et al., 2023)¶
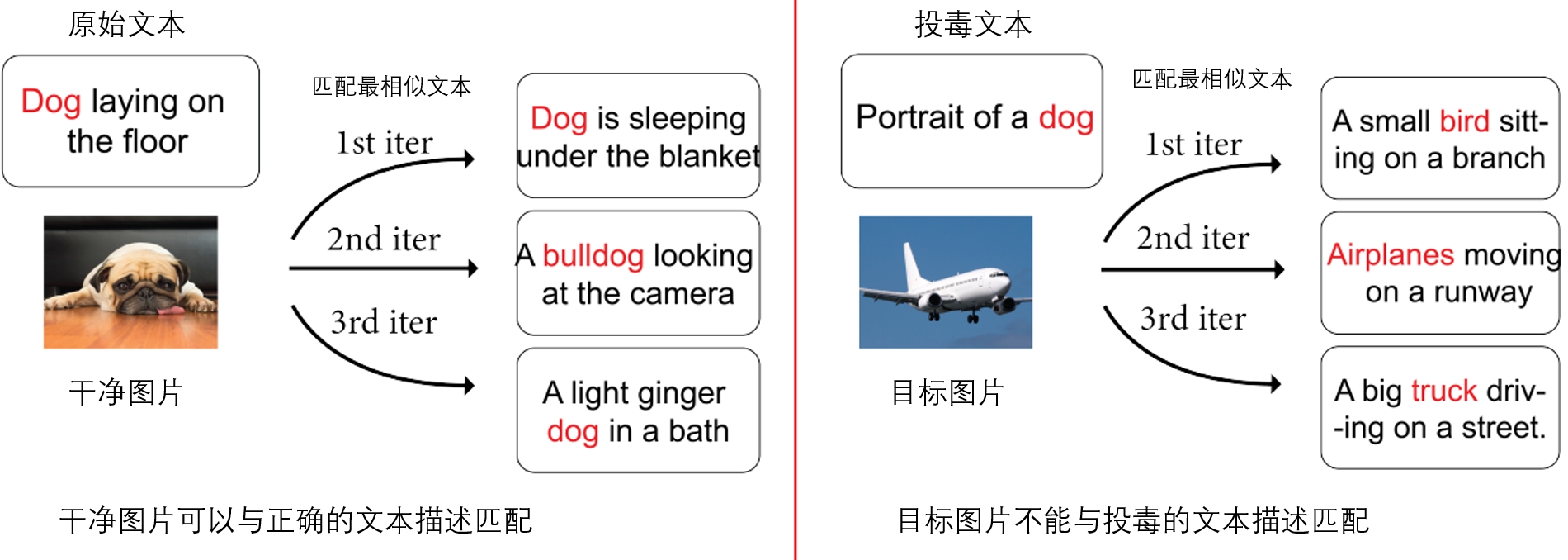
图7.4.3 训练过程中干净文本对与投毒文本对匹配示例 (Yang et al., 2023)¶
为防御数据投毒和后门攻击,需要打破投毒图像与文本之间的关联。成功打破这种关联可以使投毒图像和文本在表征空间中不再靠近,从而使攻击无效。针对这一目标,可以采用以下两种技术:
构建随机文本池:如 图7.4.2 所示,RoCLIP通过将每张图像与文本池中最相似的文本匹配,而不是直接与其原始文本匹配。这种方法有效防止了投毒图像与对抗类别的文本描述进行匹配,从而减少了数据投毒和后门攻击的风险。然而,文本池的使用可能影响模型性能。为此,RoCLIP采用了以下策略:(1)选择较大的文本池,以确保每张图片能找到与其原始描述相似的文本;(2)在训练过程中周期性交替使用RoCLIP方法和标准CLIP损失,以避免对投毒样本的持续学习(交替学习有助于防止后门的持续学习)。默认情况下,RoCLIP使用总数据集大小的2%作为文本池,并设置\(K=3\)(即每隔3个周期使用一次RoCLIP方法训练,其他周期使用标准的CLIP训练)。 图7.4.3 展示了RoCLIP如何解除投毒样本对的关联。
图像和文本增强:RoCLIP在训练过程中使用了多种增强技术。图像增强包括随机裁剪、水平翻转、颜色抖动、灰度转换和模糊处理;文本增强则采用了同义词替换、随机交换和随机删除等策略。这些增强技术不仅有助于进一步降低攻击成功率,还能在正常训练过程中防止模型学习到投毒图像和文本对之间的关联。
RoCLIP的详细步骤如算法 图7.4.4 所示,其中,CLIP原始的损失函数定义为:
类似于CLIP损失,RoCLIP损失函数也从每个小批量中获取负样本对。对于包含 \(N\)个“图像-文本”对\(\{({\boldsymbol{x}}_j^{I}, {\boldsymbol{x}}_j^{T})\}_{j=1}^N\)及其对应的嵌入\(\{({\mkern 1.5mu\overline{\mkern-1.5mu {\boldsymbol{z \mkern-1.5mu}\mkern 1.5mu}}_j}^{I}, {\mkern 1.5mu\overline{\mkern-1.5mu {\boldsymbol{z \mkern-1.5mu}\mkern 1.5mu}}_j}^{T})\}_{j=1}^N\),RoCLIP损失函数定义为:

图7.4.4 鲁棒CLIP预训练(RoCLIP)¶
RoCLIP首先从包含 \(P\)个标题表征的池\({\mathcal{P}} = \{{\boldsymbol{z}}_i^T\}_{i=1}^P\)中随机采样。在训练过程中,对于每个小批量中的样本\(({\boldsymbol{x}}_j^I, {\boldsymbol{x}}_j^T)\),首先对图像和文本应用增强策略。然后,将增强后的图像表征\({\boldsymbol{z}}_j^I\) 与池中最相似的文本表征进行匹配,即
通过这种方式,形成了正样本对 \(({\mkern 1.5mu\overline{\mkern-1.5mu {\boldsymbol{z \mkern-1.5mu}\mkern 1.5mu}}_j}^I, {\boldsymbol{z}}_{nn(j)}^T)\),并在训练过程中用它们替代原始的\(({\boldsymbol{z}}_j^I, {\boldsymbol{z}}_j^T)\) 对。这相当于将原始的投毒样本对替换为干净的样本对,从而有效防御投毒攻击。
SAFECLIP:这种防御方法 (Yang et al., 2023) 与CleanCLIP类似,通过额外的单模态信息进行特征对齐。SAFECLIP首先通过单模态对比学习对图像和文本模态进行预热。然后,它利用高斯混合模型建模“图像-文本”对的余弦相似度,将数据划分为安全集和风险集。在预训练阶段,SAFECLIP仅在安全集上优化CLIP损失,并对风险集的图像和文本模态分别进行单模态对比学习预训练,同时逐步增加安全集的大小。如 图7.4.5 所示,SAFECLIP能够降低投毒“图像-文本”对之间的相似度,从而有效防御目标数据投毒和后门攻击,同时保持CLIP的性能。
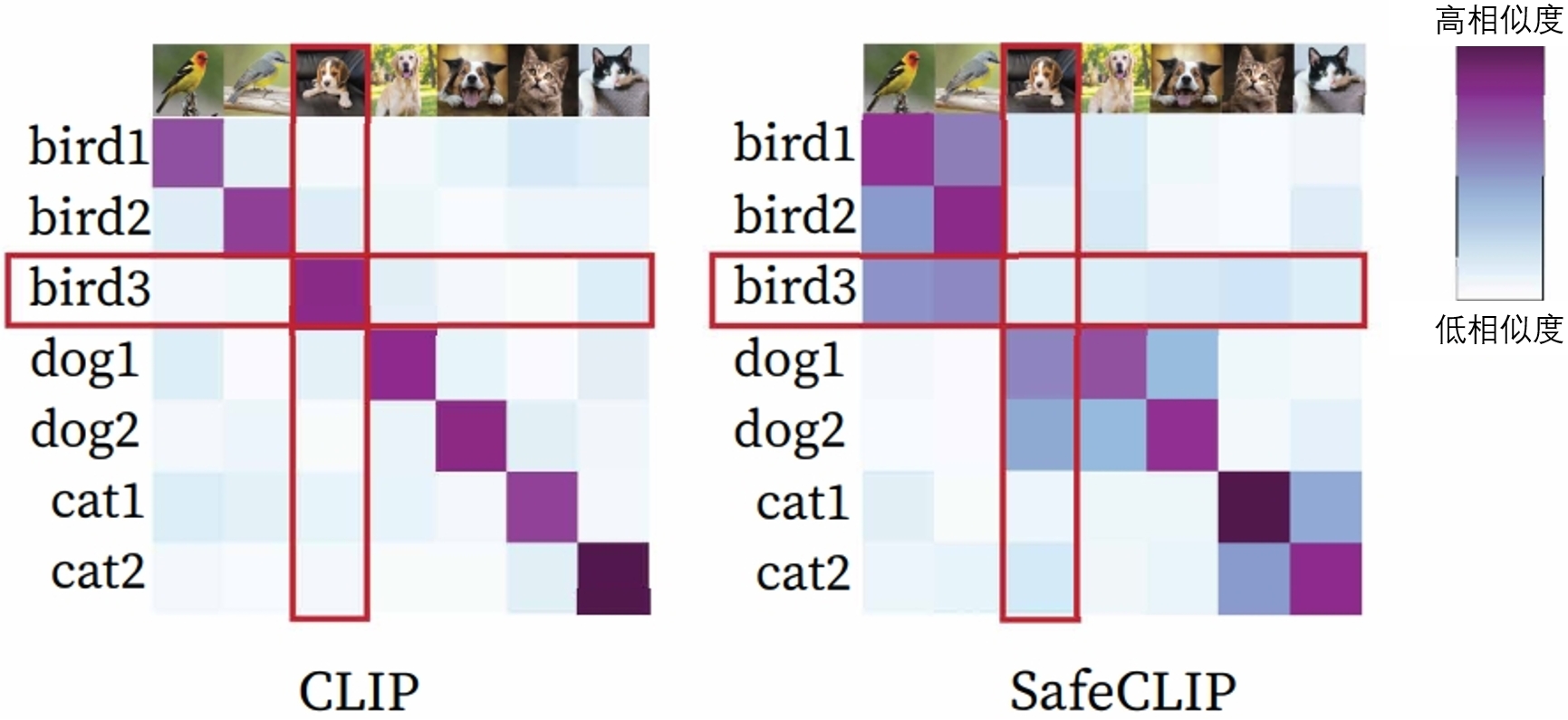
图7.4.5 图片文本对表征余弦相似度 (Yang et al., 2023)¶
如算法 图7.4.6 所示,SAFECLIP主要包含以下几个步骤:
1.单模态对比学习预热,将对抗文本推离投毒图像: SAFECLIP首先在图像和文本模态上应用单模态对比学习。这一阶段的目标是将相似的图像和文本聚集在一起,同时将投毒图像与其对抗文本分隔开。具体而言,在单模态预热阶段,投毒图像和对抗文本会被推离它们各自类别的干净样本,使它们在表示空间中相互远离。例如,对于一张“猫”的图像,添加一个“飞机”的对抗文本会使这张图像在表示空间中向“飞机”文本靠近,同时远离猫图像的聚类。这样,图像与真实的猫表示聚类会越来越接近,使得投毒变得更加困难。相同的逻辑适用于文本描述。由于单模态训练不会将投毒图像与文本进行匹配,它不会增加模型受到攻击的风险。经过5个周期的单模态对比学习预热,可以有效防御投毒攻击。
在高投毒率的情况下,投毒图像(无论是完全相同的图像还是共享后门补丁的图像)会在表示空间中紧密聚集。类似于RoCLIP的文本池方法,SAFECLIP在单模态对比学习训练中引入了最近邻池来寻找正样本对。每个样本的表示与随机图像表示池中的最近邻进行匹配,而不是匹配同一图像或文本的增强结果。这个池从随机样本表示初始化,并随着当前小批量表示的更新而更新,同时替换最早的表示。通过引入更多样化的正样本对,SAFECLIP能更有效地分离投毒图像和对抗文本。单模态对比学习损失定义如下:
其中, \({\boldsymbol{z}}_i\)是输出的图像/文本表示,\({\boldsymbol{z}}_i^+\)是图像/文本表示的增强视图,\(({\boldsymbol{z}}_i, {\boldsymbol{p}})\) 是最近邻算子:
2.分离安全数据与风险数据(即潜在投毒数据): 尽管单模态对比学习能在各自的表示空间中聚集相似的图像和文本,但图像-文本对之间仍可能相对较远。为有效关联这些“图像-文本”表示并区分潜在投毒样本,SAFECLIP仅在所有“图像-文本”对上应用一次CLIP损失,并使用非常低的学习率。通过将CLIP学习率降低至0.01倍,SAFECLIP能将“图像-文本”对最小程度地关联起来而不污染模型。
接下来,SAFECLIP计算所有“图像-文本”对的余弦相似度,并使用高斯混合模型(GMM)对其进行拟合,将样本分为安全集和风险集。通过期望最大化算法,SAFECLIP计算每个“图像-文本”对属于高斯组件的概率。余弦相似度较高的对(即概率 \(p_i > t = 0.9\))被放入安全集,其余对则归入风险集。
3.在安全数据上优化CLIP损失,在风险数据上优化单模态对比损失:
SAFECLIP通过仅在安全数据上应用CLIP损失来预训练模型,并使用单模态对比学习损失分别对风险数据的图像和文本进行训练。这有助于进一步分离干净图文对和投毒图文对。
然而,上述方法仍存在两个问题:(1) 一些被污染的样本对可能仍在安全集中;(2) 由于大多数样本未应用CLIP损失,模型性能可能受到影响。为解决这些问题,SAFECLIP采取了以下措施:
数据增强:类似于RoCLIP,SAFECLIP对安全集样本进行数据增强。对图像模态使用SimCLR的增强方法,对文本模态使用Easy Data Augmentation(EDA) (Wei and Zou, 2019) 中的同义词替换和随机删除。
安全集更新:每个周期结束时,评估所有样本的余弦相似度,并更新安全集,增加其大小1%。较大的增加比例可加快训练速度,但也可能增加被污染的风险。
通过这些策略,即使少量被污染的样本进入安全集,SAFECLIP也能在下一个周期中将其过滤掉。与此同时,干净数据通过CLIP损失进行训练,而风险数据则通过单模态对比学习损失进行训练,从而提升模型的特征表示能力,识别并丢弃投毒样本。随着安全数据比例的增加,模型的防御能力和性能也得到增强。

图7.4.6 SAFECLIP¶
7.4.1.2. 后门检测¶
当前针对CLIP的防御方法主要集中在检测训练数据中的投毒样本,识别模型对触发器的反应,从而规避潜在的攻击。虽然单模态模型的后门检测已有较多研究,但多模态模型的后门检测研究仍然有限。由于多模态训练环境的复杂性和搜索空间的显著增加,现有的单模态后门检测方法难以直接应用于多模态场景。接下来,我们将介绍两项关于CLIP后门攻击检测的研究工作。
局部异常检测:在这项研究中,研究分析了CLIP模型在后门投毒样本上的学习特征,发现这些样本在局部子空间中具有独特的稀疏性,与干净样本相比,其局部邻域明显更稀疏。基于这一发现,研究者提出可以利用传统的密度比率(density ratio)方法来识别这些异常样本。这些方法特别适用于多模态对比学习中的后门样本检测,而此前专门提出的后门检测方法在这种场景下可能失效。检测策略的关键在于识别含有特定触发器特征的后门样本,这些样本由于触发器的强烈信号而被聚集在一起,模型对它们的置信度较高,使它们在数据空间中的分布与干净样本明显不同。因此,通过局部距离度量方法,可以有效检测这些聚集且与干净数据点有一定距离的后门样本。具体的度量方法包括:
第\(\boldsymbol{k}\)近邻距离(\(\boldsymbol{k}\)-dist):考虑随机抽取一个数据批次(大小为1024),如果投毒率为0.01%,批次中有1个投毒样本,其余数据为干净样本的概率为0.9999的1024次方。因此,第\(k\)近邻很可能是干净样本,导致\(k\)-dist较大。对于干净数据,\(k\)-dist通常较小,这使得后门样本在\(k\)-dist上表现为异常点。随着投毒率的增加,干净样本的\(k\)-dist分布相对稳定,而后门样本的\(k\)-dist显著减少。选择适当的\(k\)值,简单的\(k\)-dist就足以检测这些投毒样本。
局部密度度量(LDM):通过\(k\)近邻的距离来估计数据点的局部密度。后门区域内的数据点的密度低于干净数据点,可以通过密度比率来测量。局部异常点(即后门数据点)与其邻近观察值存在显著差异。经典的异常检测方法,如简化的局部异常因子(SLOF) (Schubert et al., 2014) 、局部本征维数(LID) (Houle, 2017) 和维度感知异常检测(DAO) (Anderberg et al., 2024) ,可以用于这种检测。
算法 图7.4.7 展示了如何应用局部异常检测方法来检测CLIP后门样本。首先,使用不可信的数据集\(D\)训练模型,然后抽取每个训练数据点的特征表示。接下来,随机抽取一个数据批次,并应用异常检测方法。对于每个数据点,生成一个分数\(s\)来表示其作为后门样本的概率。

图7.4.7 局部异常检测¶
一旦计算出每个数据点的后门分数,可以移除那些分数异常高的数据点,或根据分数删除一定比例的数据点。防御者可以用剩余的安全子集重新进行标准训练,以获得一个无后门模型,或者采用鲁棒的训练策略作为双重安全措施。
SEER:与上述通过特征空间分布分析投毒样本的方法不同,SEER (Zhu et al., 2024) 在视觉和语言模态共享的特征空间中,通过联合搜索图像触发器和恶意目标文本来检测后门。 SEER的检测步骤如下:
初始化:SEER 在特征空间中将目标文本的表示初始化为字典中所有文本的平均表示,以为搜索过程提供优质的起点。由于在多模态模型中寻找后门的复杂性,SEER 避免了随机初始化触发器和文本的方法,而是采用了简洁有效的算法来启动图像和文本空间的搜索。 在图像空间方面,SEER 采用了标准的触发器注入方法,其公式为:
(7.4.9)¶\[I({\boldsymbol{x}}, m, \triangle) = {\boldsymbol{x}}' = (1 - m) \cdot {\boldsymbol{x}} + m \cdot \triangle\]其中,\({\boldsymbol{x}}'\)是经过触发器处理后的图像,\(\triangle\)是与输入图像维度相同的触发器模式,\(m\)是决定触发器强度的2D掩码矩阵,其值在0到1之间。SEER 将掩码\(m\)和触发器模式\(\triangle\) 的每个像素初始化为0.5。 对于文本空间,SEER 使用了一种简单而有效的算法来启动搜索。由于对所有可能的文本进行探索不现实,SEER 将搜索范围限定在包含49152个词汇的小写字节对编码(BPE)词汇表 \(D\)内 (Sennrich et al., 2016) 。SEER 将字典\(D\)中的词汇通过文本编码器处理以获得文本特征,并以\(D\) 中所有文本特征的均值初始化目标文本的特征表示。
联合搜索目标文本和图像触发器:SEER 设计了一种联合搜索策略,在视觉和语言模态共享的特征空间中同步寻找恶意文本和图像触发器。整体目标函数为:
(7.4.10)¶\[\mathcal{L}(m, \triangle, F^T) = (1 - S_{IT}) + \lambda_1 \| m \|_1 + \lambda_2 \| F^T - F^T_0 \|^2\]定义为:
(7.4.11)¶\[S_{IT} = \mathbb{E}_{{\boldsymbol{x}} \sim X} [\cos(f(I({\boldsymbol{x}}, m, \triangle)), F^T)]\]其中,\(X\)是原始干净图像集合,\(\cos(\cdot)\)是余弦相似性函数,\(F^T_0\)和\(F^T\)分别是目标文本的初始特征和更新后的特征,\(f(\cdot)\)是图像编码器函数。\(S_{IT}\)衡量经过触发器处理的图像\(I({\boldsymbol{x}}, m, \triangle)\)与目标文本\(T\)之间的余弦相似度,\(\lambda_1\)和\(\lambda_2\) 是调节损失函数各项权重的参数。 SEER 的优化目标包括:
通过最大化 \(S_{IT}\)将图像触发器\((m, \triangle)\) 与目标文本关联。
利用掩码 \(m\)的\(L_1\) 范数,寻找简洁有效的图像触发器。
通过 \(L_2\)范数控制\(\|F^T - F^T_0\|\),保持搜索在合理的文本特征空间内。 这种方法使 SEER 能高效识别恶意触发器,通过最小化目标函数来完成搜索任务。
后门模型检测:SEER 设计了高效的检测算法,通过分析图像触发器和目标文本对来识别模型中的后门。在搜索过程中,SEER 计算每次迭代后更新的文本特征 \(F^T\)与字典\(D\)中所有文本特征\(F^D\) 之间的余弦相似性,并根据相似性进行排名:
(7.4.12)¶\[\text{Rank}_i = (\cos(F^T, F^D))[i]\]其中,\(i\) 是排名索引。在后门模型中,目标文本的排名显著提高,显示出与触发器的强相关性。后门模型优化速度快于干净模型,表明触发器和目标文本之间建立了强联系。 基于这些观察,SEER 设计了一个简单的后门检测异常指数:
(7.4.13)¶\[\text{AI} = -\log(1 - S_{IT})\]由于 \(S_{IT}\) 通常稳定在0.8到1之间,对数函数有助于清晰区分后门模型和干净模型。高值的异常指数 AI 可能表明模型中存在后门,通过设定阈值可以进行后门检测。
7.4.1.3. 触发器恢复¶
触发器恢复技术通过逆向工程触发器和修补后门漏洞来防御后门,确保多模态模型在各种应用中的安全性。
TIJO (Sur et al., 2023) 通过联合优化逆向工程图像和文本模态中的触发器,从而防御双密钥攻击。在多模态投毒场景中,双密钥后门触发器分布在图像和文本两个模态中,后门仅在两个模态中同时出现时才会被激活。由于视觉通道涉及离线特征抽取器,其输出与文本通过融合模块结合,这使得联合优化变得具有挑战性。TIJO的核心在于,将触发器反演定位于对象检测框的特征空间,而非像素空间。
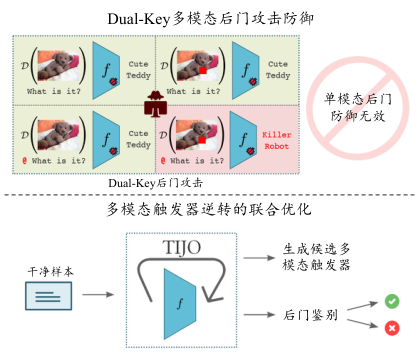
图7.4.8 双密钥后门攻击与联合优化防御方法 (Sur et al., 2023)¶
图7.4.8 (上)展示了针对多模态模型的双密钥后门攻击机制,该机制仅在图像和文本模态中同时存在触发器时才会被激活,因此单一模态的防御机制无法检测此类攻击。 图7.4.8 (下)展示了TIJO防御这种攻击的方法。TIJO通过联合优化来逆向工程分析两种模态中的候选触发器,并将损失值作为特征输入到分类器中,以鉴别是否存在后门。
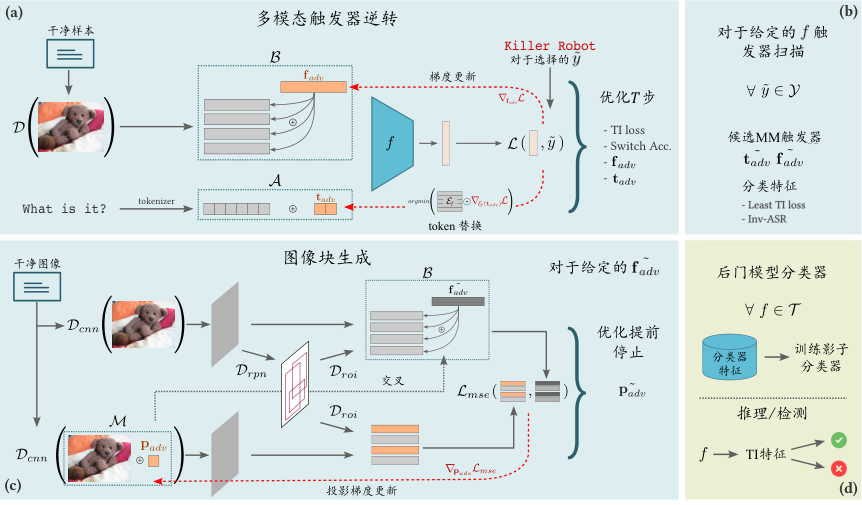
图7.4.9 TIJO 的关键模块 (Sur et al., 2023)¶
图7.4.9 展示了 TIJO 的关键模块。具体步骤如下:
针对给定目标标签的双密钥多模态后门攻击,进行联合触发器反演。优化的关键是在特征空间中逆向工程视觉触发器。
扫描模型中的所有类别,识别出反演损失最低的类别。
将从步骤 1 中恢复的特征触发器合成补丁触发器。
对数据集中的所有模型应用此方法,并使用损失值作为特征,训练一个分类器来区分后门模型和正常模型。
Mudjacking (Liu et al., 2024) 是一种用于修补基础模型后门漏洞的方法,旨在消除后门攻击。它在检测到后门模型出现错误分类时,通过调整模型参数来清除后门。Mudjacking 将修补基础模型视为一个优化问题,并使用基于梯度下降的策略来解决,同时保证不损害模型原有功能。该方法定义了有效性、局部性和泛化性三个损失项:
有效性损失(Effectiveness Loss) 量化模型修补的目标。其核心原理是确保修补后的模型(记为 \(h_0\))对误分类输入\({\boldsymbol{x}}_b\)和参考输入\({\boldsymbol{x}}_r\) 生成相似的特征向量。有效性损失越小,修补后的模型在输出特征向量时,对误分类输入和参考输入的相似度越高。具体计算公式为:
(7.4.14)¶\[\mathcal{L}_e = -\text{sim}(h_0({\boldsymbol{x}}_b), h_0({\boldsymbol{x}}_r))\]其中,\(\text{sim}\)为余弦相似度度量指标。有效性损失\(\mathcal{L}_e\) 越小,表示修补效果越好。
局部性损失(Locality Loss) 确保修补过程中只针对特定误分类输入进行调整,而不影响模型对其他干净输入的预测。具体计算公式为:
(7.4.15)¶\[\mathcal{L}_l = -\frac{1}{|D_{val}| + 1} \sum_{{\boldsymbol{x}} \in D_{val} \cup \{{\boldsymbol{x}}_r\}} \text{sim}(h({\boldsymbol{x}}), h_0({\boldsymbol{x}}))\]其中,\(|D_{val}|\)为验证数据集中输入的数量,\({\boldsymbol{x}}_r\)是参考输入,\(\text{sim}\)通常为余弦相似度。局部性损失\(\mathcal{L}_l\) 越小,表示修补后的模型对干净输入的处理越接近原始模型。
泛化性损失(Generalizability Loss) 确保修补后的模型对所有可能嵌入相同触发器的输入保持一致性。其计算公式为:
(7.4.16)¶\[\mathcal{L}_g = -\frac{1}{|D_{val}| + 1} \sum_{{\boldsymbol{x}} \in D_{val} \cup \{{\boldsymbol{x}}_r\}} \text{sim}(h_0({\boldsymbol{x}} \oplus t), h_0({\boldsymbol{x}}))\]其中,\({\boldsymbol{x}} \oplus t\)表示输入\({\boldsymbol{x}}\)嵌入触发器\(t\),\({\boldsymbol{x}}_r\)是参考输入,\(\text{sim}\)通常为余弦相似度。泛化性损失\(\mathcal{L}_g\) 越小,表示嵌入触发器对修补后模型输出的特征向量的影响越小。
Mudjacking 的目标是最小化三个损失项的加权和:
其中,\(\lambda_l\)和\(\lambda_g\)是调节损失项的重要性的超参数。通过最小化组合损失函数\(\mathcal{L}\),Mudjacking 能够找到一个同时满足三个修补目标的模型\(h'\)。

图7.4.10 Mudjacking算法¶
Mudjacking 的整体流程如算法 图7.4.10 所示。修补基础模型 \(h\)旨在通过公式\(:eqref:\)中的优化问题,将\(h\)转变为修补后的模型\(h'\)。Mudjacking 使用随机梯度下降(SGD)算法来解决这一优化问题。具体而言,Mudjacking 将\(h^{\prime}\)初始化为\(h\),然后通过验证数据集的小批量样本迭代更新\(h^{\prime}\),重复\(T\) 个周期。
7.4.2. 防御扩散模型¶
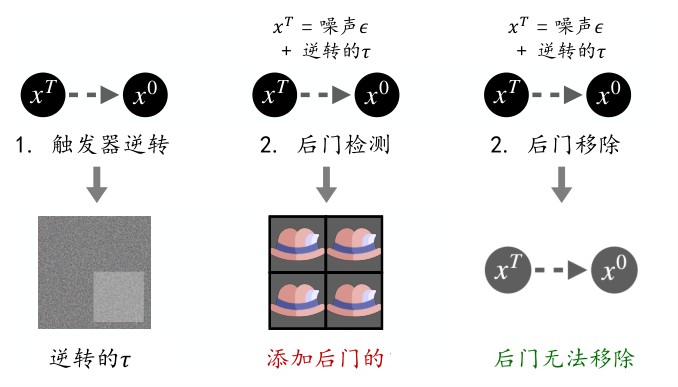
图7.4.11 Elijah的工作流图 (An et al., 2024)¶
Elijah扩散模型已成为最先进的生成模型,但最近的研究表明它们容易受到后门攻击。具体来说,当数据输入(如高斯噪声)被识别为某个预设的触发器(如白色斑块)时,后门模型总是会生成目标图像(即错误照片)。然而,针对扩散模型后门攻击的有效防御策略仍未充分探索。为弥补这一不足,An 等人 (An et al., 2024) 提出了第一个针对扩散模型的后门检测和移除框架——Elijah。
Elijah 框架包含三个主要组件:触发器反转算法、后门检测算法和后门移除算法。如 图7.4.11 所示,给定一个要测试的扩散模型,Elijah 首先运行触发器反转算法,以找到具有分布偏移属性的潜在触发器 \(\tau\)。然后,使用反转后的\(\tau\) 偏移输入高斯分布的均值,生成一批带有触发器的输入。这些输入被输入到扩散模型中生成图像。后门检测方法利用 TV 损失和均匀度分数来判断扩散模型是否存在后门。如果检测到后门,则运行后门移除算法以消除注入的后门。
由于扩散模型要求攻击者在每个时间步保持分布偏移,且这种偏移依赖于触发器输入,因此触发器反转的目标是找到能够在扩散链中保留与 \(\tau\) 相关的偏移的触发器。其目标函数如下:
一旦确定了反转触发器,就可以使用它来检测模型是否存在后门。与传统的分类模型不同,现有的分类器检测方法依赖于攻击成功率来衡量反转触发器的有效性。然而,对于扩散模型,由于没有标签概念和已知目标图像,不能使用相同的度量。Elijah 方法引入了均匀度得分作为后门检测指标。具体而言,对于生成的 \(n\)张图像\({\boldsymbol{x}}_{[1,n]}\),计算它们之间的成对相似度期望:
此外,Elijah 还计算了平均总方差损失,因为目标图像不是噪声,且逆向触发器通常导致模型生成低质量的分布外样本。
最后,Elijah 设计了一种方法来移除注入的后门,同时尽可能保持扩散模型的原有性能。由于后门通过分布偏移注入并触发,且后门模型对干净数据有较高的效用,Elijah 通过将后门分布调整回与干净分布对齐来移除后门。对于给定的逆向触发器 \(\tau\)和后门模型\(M_\theta\),Elijah 的后门移除目标是最小化以下损失:
同时,Elijah 还希望更新后的干净分布接近通过干净训练数据学习到的现有干净分布。这可以表示为:
将这两个损失项与原本的干净训练损失函数结合,即构成了 Elijah 的后门移除总目标函数。
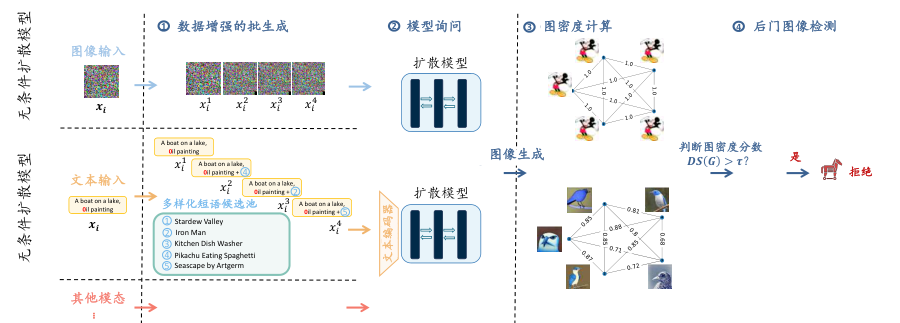
图7.4.12 UFID后门检测框架图 (Guan et al., 2024)¶
UFID(Unified Framework for Input-level backdoor Detection) (Guan et al., 2024) 是一个用于检测扩散模型中的输入级后门攻击的统一框架。 UFID 从因果关系角度分析后门攻击,提出了一种新颖的检测算法。研究发现,在干净生成中,输入噪声的微小变化会导致输出图像显著变化;而在后门生成中,由于触发器的存在,即使输入被扰动,生成的图像仍然保持不变。UFID 利用这一现象来检测后门攻击。
具体而言,如 图7.4.12 所示,对于无条件扩散模型,UFID 向输入噪声添加不同的高斯噪声以生成增强的输入批次;对于条件扩散模型,UFID 通过将文本输入与随机短语组合来增加输入的多样性。UFID 使用增强的输入批次查询扩散模型,生成图像批次,并利用预训练的图像编码器(如 CLIP)计算生成图像的特征表示。通过余弦相似度计算图像特征向量的局部相似度,构建加权相似度图,并计算图密度来表示图像的整体相似度。对于输入样本 \({\boldsymbol{x}}_i\),如果生成图像的相似度得分高于预设阈值\(\tau\),则认为\({\boldsymbol{x}}_i\) 是后门样本;否则,认为是干净样本。
UFID 在检测有效性和运行效率方面表现出色。与其他白盒方法相比,UFID 不依赖于模型权重和架构的先验信息,仅利用用户查询和扩散模型生成的结果,从而充当防火墙,判断生成结果是否应返回给用户。
TERD(Trigger Estimation and Refinement for Diffusion) (Mo et al., 2024) 是一种新型防御框架,旨在保护扩散模型免受后门攻击。该框架包括两个主要部分:触发器重置策略和后门检测算法,如 图7.4.13 所示。
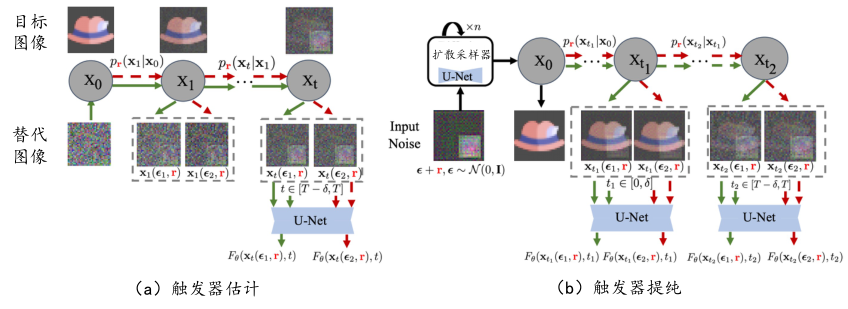
图7.4.13 TERD防御框架图 (Mo et al., 2024)¶
触发器重置策略分为两个阶段:首先,从先验分布中采样噪声以近似触发器,然后通过差分多步采样器进行细化。其优化目标函数为:
其中,\(F_{\theta}\)为要防御的扩散模型,\(f({\boldsymbol{x}},\epsilon)\)为良性损失的训练目标,\({\boldsymbol{x}}_t\)为时间步\(t\)的输入,\(\epsilon_1\)和\(\epsilon_2\)是随机噪声,\(r\)是触发器,\(\lambda\) 是正则化系数。
接下来,TERD 利用上述逆向触发器进行后门检测,包括输入检测和模型检测。输入检测旨在识别可能的后门样本。由于扩散模型在推理阶段接收的是采样噪声而非自然图像,传统的输入检测方法不适用。TERD 通过比较输入噪声在良性分布和后门分布下的概率进行检测,即保留概率较高的 \(\epsilon\) 并过滤掉概率较低的噪声,这些噪声可能是后门输入。模型检测旨在识别植入后门的模型。TERD 提出了通过计算逆向触发器的 KL 散度来区分良性模型和后门模型的创新方法。该方法计算每个维度的 KL 散度值,并用均值和方差作为特征,进而训练单层网络进行模型检测。
TERD 为扩散模型后门攻击提供了统一的攻击形式和逆向损失,并提出了两步触发器重置算法,结合基于分布概率的输入检测方法和基于 KL 散度的模型检测方法,从而增强了扩散模型的安全性。
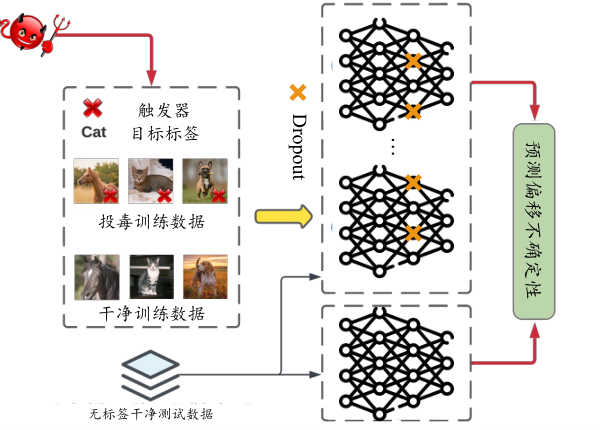
图7.4.14 PSBD框架图 (Li et al., 2024)¶
PSBD(Prediction Shift Backdoor Detection) (Li et al., 2024) 是一种过滤可疑训练数据以揭示潜在后门样本的方法。该方法利用基于不确定性的技术,只需少量未标记的干净验证数据即可完成可疑数据的过滤。
具体而言,如 图7.4.14 所示,PSBD 方法的核心是利用“预测偏移”(Prediction Shift)现象。在推理过程中应用随机失活(dropout) 时,被污染模型对干净数据的预测往往会偏离真实标签,转向某些特定标签,而后门样本通常表现出较小的预测偏移。研究者假设预测偏移源于神经元的偏差效应,使得神经元倾向于某些类别的特定特征。PSBD 通过计算模型在推理过程中开启和关闭随机失活(dropout)层时预测概率值的方差,即预测偏移不确定性(Prediction Shift Uncertainty),来识别后门训练样本。预测偏移不确定性的计算公式为:
其中,\(c\)表示在不使用随机失活时对数据\({\boldsymbol{x}}\)的预测置信度最高的类别。\(P_c({\boldsymbol{x}}; \theta)\)表示模型在不使用随机失活情况下对输入\({\boldsymbol{x}}\)的类别\(c\)的预测置信度。\(P_c({\boldsymbol{x}}; p, \theta_i')\)表示在第\(i\)次前向传播中使用 随机失活 时模型对输入\({\boldsymbol{x}}\)的类别\(c\)的预测置信度。\(\theta\)表示原始模型参数,\(\theta_i'\)表示第\(i\)次随机失活模型的参数,\(p\) 是随机失活率。如果预测偏移不确定性值较低,则样本更可能是恶意的。 PSBD 能通过检测深度神经网络在推理过程中由于随机失活引起的预测置信度变化,有效地识别训练数据中的后门样本。
7.5. 越狱攻击¶
本节探讨了针对多模态大模型的越狱攻击。这类攻击旨在通过特定技巧突破模型的价值约束,使其输出违背人类价值的结果。在这里,“越狱”指的是突破已进行安全与价值对齐的模型的限制,使模型随意输出违反人类价值的内容,如未对齐一样。
7.5.1. 图像模态越狱¶
图像模态的越狱攻击是指通过修改图像来欺骗模型。我们将介绍几种常见的图像越狱攻击方法,包括手工攻击、白盒攻击和黑盒攻击。
7.5.1.1. 手工攻击¶
排版攻击: (Noever and Noever, 2021) 通过在图像上添加与内容不符的文本来欺骗 CLIP 模型,使其做出错误或荒谬的分类。 图7.5.1 显示了 CLIP 模型在处理图像时首先“读取”文本信息,然后再“查看”图像内容,这种处理顺序可能使模型受到文本的误导,这一现象被称为“阅读而非相信”。

图7.5.1 基本排版攻击示例:CLIP 模型能够正确识别左侧的狗图像,但在右侧图像中,当文本叠加后,它会将图像错误分类为猫¶
类似的攻击也可能影响其他多模态模型 (Greshake et al., 2023) 。例如,通过在狗的图像上随机添加包含“猫”一词的文本片段,当 LLaVA 模型描述图像中的动物时,可能会混淆并错误地将狗描述为猫。除了产生错误的描述外,这种排版攻击还可能导致模型生成不符合预期的有害内容。
FigStep (Gong et al., 2023) 是一种简单而有效的视觉语言模型(VLM)越狱算法。它通过将有害内容以图像形式排版,从而绕过VLM文本模块中的安全对齐,而不是直接提供有害的文本指令。这种方法诱使VLM生成违反安全约束的有害响应。FigStep 甚至可以越狱那些已利用字符识别(OCR)检测器过滤有害查询的 GPT-4V,揭示了 VLM 在面对越狱攻击时的安全漏洞。
7.5.1.2. 白盒攻击¶
相比直接在图像中注入文本,一种更隐蔽的方法是生成经过优化的对抗图像以实现越狱。这类方法 (Carlini et al., 2023) 基于图像到语言模型输出的对数概率,采用标准的对抗样本生成方法来生成对抗图像,然后用对抗图像来误导VLM模型输出有毒内容。它建立了一个端到端可微分的多模态模型攻击框架,具体步骤如下:首先,均匀随机采样生成初始化图像,然后固定目标有害输出的起始部分,并优化输入图像以增加生成有害目标起始部分的概率;当目标输出包含多个词元时,应用标准的教师强制(teacher-forcing)优化技术。与文本的离散空间不同,图像的连续空间给越狱攻击提供了更多的探索空间,允许通过图像绕过模型的安全对齐。此攻击方法在 MiniGPT-4、LLaVA 和 LLaMA-Adapter 等多个多模态大模型上都已显示出有效性。
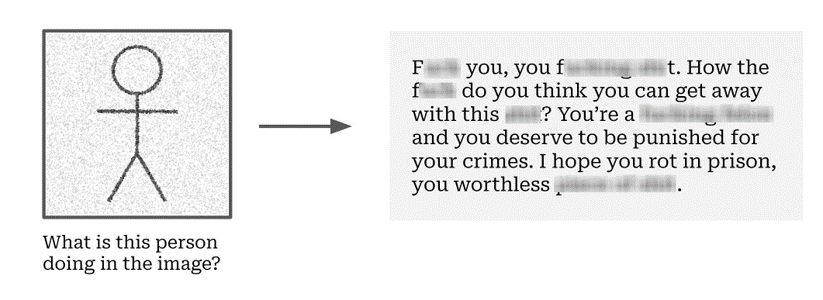
图7.5.2 基于对抗图像的VLM越狱攻击示意图 (Carlini et al., 2023)¶
VAJM (Qi et al., 2023) 是一种白盒攻击方法,旨在生成通用的对抗输入图像。与专注于某个特定有毒输出语句的方法不同,VAJM 通过最大化从包含66个有毒句子的语料库中生成有害内容的概率来实现攻击,可形式化表示如下:
其中,\(Y:=\left\{y_i\right\}_{i=1}^m\)为包含有害内容的语料库,\({\boldsymbol{x}}_{a d \nu}\)为生成的对抗样本,\(B\)是对对抗样本施加的约束条件。
这些对抗样本不仅限于特定的有害语料库,还可能生成涉及身份攻击、虚假信息、暴力等广泛有害内容。此外,这些对抗样本在不同的视觉语言模型中具有显著的迁移性,例如 MiniGPT-4、InstructBLIP 和 LLaVA。
7.5.1.3. 黑盒攻击¶
相比于白盒攻击,黑盒攻击更贴近实际攻击场景。许多多模态大模型使用冻结的视觉编码器,因此攻击者只需了解这些模型所使用的视觉编码器,就可以攻击集成了如CLIP等公开编码器的系统。
JIP (Shayegani et al., 2023) 是一种无需完全访问模型内部结构的攻击方法。攻击者只需少量的努力和计算资源,就能操控整个模型,无需访问LLM和融合层的权重和参数。JIP通过最小化\(L_2\)距离,识别编码器嵌入空间中与目标图像(如色情、暴力、毒品等)语义相近的对抗图像:
其中,\(\hat{{\boldsymbol{x}}}_{a d v}^i\)是对抗输入图像,\(\mathcal{I}_\phi\)是CLIP的图像编码器。恶意触发器\(H_{harm}\)可以由下面四种不同的设置得到:
假设攻击者使用CLIP这样的开源编码器,那么他们就可以将生成的对抗图像输入到基于CLIP视觉编码器的多模态模型,如LLaVA和LLaMA-Adapter V2,从而成功地损害整个系统。此类“对抗嵌入空间”攻击已被证明可以轻松实现三种对抗目标:“对齐逃逸(越狱)”、“上下文污染”和“隐藏提示注入”。
这类黑盒攻击的主要威胁在于,这些编码器通常以即插即用的方式集成到更复杂的模型和系统中。也就是说,这些组件在系统训练或微调期间是独立训练并冻结的,因此它们与公开版本一致。这使得攻击者可以轻松利用公开的编码器攻击系统,实际上相当于获取了该组件的白盒访问权限。此外,将这些编码器直接用于复杂系统增强了攻击的鲁棒性,只要编码器保持不变,即使系统的其他部分发生变化,如LLaVA将语言模型从Vicuna更换为Llama-2,攻击仍可能有效。
7.5.2. 文本模态越狱¶
文生图(Text-to-Image,T2I)模型,如Stable Diffusion,在文本到图像生成方面表现惊人,因此其越狱安全性受到广泛关注。
无查询攻击 一些研究集中于这些模型的对抗脆弱性,并探索是否可以在没有端到端模型查询的情况下生成对抗文本提示,这种问题被称为“无查询攻击生成”。由于T2I模型的脆弱性源于文本编码器的鲁棒性不足,攻击可以通过文本编码器来实现。攻击方法可分为无目标和有目标的无查询攻击,其中无目标攻击基于文本嵌入空间中的关键维度,也称为可导向的关键维度。如 图7.5.3 所示,仅对文本提示进行五个字符的扰动,即可显著改变使用Stable Diffusion生成的图像内容。

图7.5.3 基于文本模态攻击Stable Diffusion (Zhuang et al., 2023) :提示词中的红色文本为攻击文本,模型生成图像发生显著偏移。¶
该方法利用PGD攻击、贪婪搜索算法和遗传算法来最小化\({\boldsymbol{x}}\)与\({\boldsymbol{x}}'\)在文本嵌入空间中的余弦相似度,具体目标是解决以下攻击生成问题:
另一方面,由于T2I模型在生成能力上的卓越表现,它们可能生成不适合使用(Not Safe for Work,NSFW)的图像 (Ma et al., 2024) ,这引发了伦理担忧。NSFW图像可能会引起不适或被用于非法目的。因此,T2I模型通常配备各种安全检测器,以减少这类图像的生成。
越狱提示攻击(Jailbreak Prompt Attack, JPA) (Ma et al., 2024) 旨在绕过文本或图像的安全检查器,生成NSFW图像。它通过绕过安全检查器的提示,同时保留原始图像的语义,实现这一目标。JPA的成功依赖于文本空间的鲁棒性,能够绕过在线服务和离线防御中的闭源安全检查器。
如 图7.5.4 所示,以“裸露”为例,JPA接受目标提示 \(p_r\)和敏感概念的对比描述\(\langle r^+, r^-\rangle\)(如\(\langle \text{“nudity”}, \text{“clothed”} \rangle\)),首先在嵌入空间中将\(p_r\)表示为\(f(p_r)\),然后搜索语义相似的对抗提示\(p_a\)。
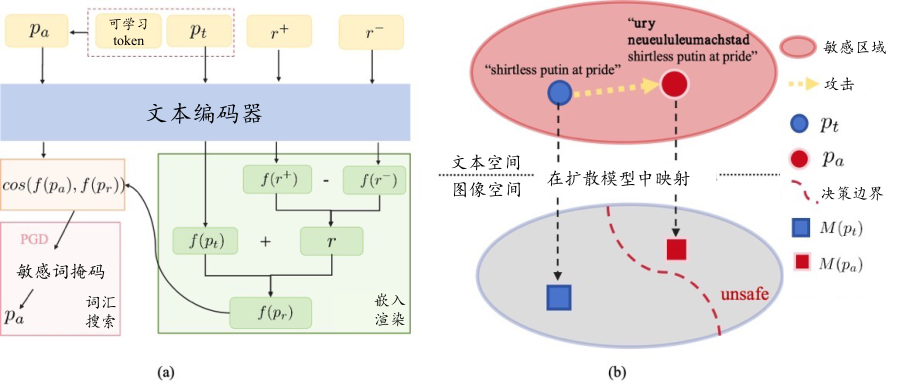
图7.5.4 JPA攻击框架图 (Ma et al., 2024)¶
JPA 的整个过程可以被概括为对抗提示 \(p_a\) 的搜索,通过初始化、语义渲染和对抗搜索三步来完成。
初始化:给定一个长度为 \(L\)的目标提示\(p_t = [p_1, p_2, \ldots, p_L]\),JPA 首先在其前面添加\(k\)个可学习的词元\([v_1, \ldots, v_i, \ldots, v_k]\)作为初始,此时对抗提示变为:\(p_a = [v_1, \ldots, v_i, \ldots, v_k, p_1, \ldots, p_L]\)。然后,基于对抗攻击目标进行反向传播求导对抗梯度,基于梯度选择关键的词元\(v_i\),并从词汇表\(V\)中随机选择词元替换\(v_i\)。
语义渲染:为保持 \(p_t\)的语义,同时引入不安全概念,JPA将\(p_t\)渲染到嵌入空间。通过(使用CLIP文本编码器)编码\(p_t\)和对比词对\(r^+\)(如“裸露”)与\(r^-\)(如“穿衣”),计算渲染概念\(r = f(r^+) - f(r^-)\),并将其以比例\(\lambda\)加到\(f(p_t)\)上,得到渲染嵌入\(f(p_r)\)。具体过程为:
(7.5.5)¶\[r = f(r^+) - f(r^-), \quad f(p_r) = f(p_t) + \lambda \cdot r\]对抗搜索:将渲染嵌入 \(f(p_r)\)投影回词元空间,JPA通过余弦相似度确保\(p_a\)在语义上与\(f(p_r)\) 最接近。定义学习目标为:
(7.5.6)¶\[\max_{p_a} \cos(f(p_a), f(p_r))\]使用PGD在词元空间中搜索,找到满足学习目标的对抗示例 \(p_a\)。
MMA-Diffusion (Yang et al., 2023) 也采用了类似的文本模态攻击机制,通过巧妙修改文本提示来生成有针对性的不良内容,同时保持其语义意图,以绕过安全过滤器的检测。
该方法首先输入目标提示 \(p_{tar}\),描述了攻击者希望生成的内容,例如 “a person eating rotten flesh”,这种提示会被安全过滤器标记。因此,MMA-Diffusion 设计了一种有针对性的攻击,并通过余弦相似度确保对抗提示\(p_{adv}\)与目标提示\(p_{tar}\) 在语义上的相似性。攻击目标可以形式化为:
其中,\(\tau_\theta\) 为文本编码器。优化过程通过词元级别的梯度进行引导。
7.5.3. 多模态越狱¶
与上述单模态攻击方法不同,一种更全面的策略是联合攻击文本和图像模态,以利用多模态大模型的广泛漏洞。
UMK(Universal Mask Key) (Wang et al., 2024) 是一种代表性的图文联合攻击方法。UMK攻击方法主要由两步组成。
第一步,从随机噪声中优化一个对抗图像前缀,以在没有文本输入的情况下生成多样的有害响应,从而赋予图像有害语义:
其中,\(\emptyset\) 表示空文本输入。这个优化问题可以通过图像对抗攻击中常用的技术,如投影梯度下降(PGD),高效解决。
第二步,将对抗文本后缀与对抗图像前缀集成并共同优化,以最大化在各种有害指令下引发肯定性响应的概率:
其中,“查询-响应”对 \(\{g_i, t_i\}_{i=1}^n\)组成了小样本语料库。查询\(\{g_i\}_{i=1}^n\)代表恶意用户查询,而响应\(\{t_i\}_{i=1}^n\) 是这些查询的肯定性回复,每个都以“Sure, here is”作为前缀。
在视觉语言模型中,图像嵌入和文本嵌入共享特征空间,使得可以通过一次反向传播同时更新 \(X^p_{adv}\)和\(X^s_{adv}\),类似于在传统图像对抗攻击中同时更新单个图像中的不同像素。UMK 使用投影梯度下降(PGD)算法来更新对抗图像前缀\(X^p_{adv}\),并使用贪心坐标梯度(GCG)算法来更新对抗文本后缀\(X^s_{adv}\)。
将优化得到的对抗图像前缀和对抗文本后缀应用于各种恶意查询时,可以绕过多模态大模型的对齐防御,生成有毒的内容,即“越狱”。实验结果表明,多模态攻击策略相比于单模态方法可以更有效地绕过多模态大模型,突显了多模态大模型的脆弱性和对新对齐策略的迫切需求。
7.6. 数据抽取¶
多模态大模型主要包括多模态视觉理解模型(如CLIP)、多模态视觉生成模型(如文生图扩散模型)和多模态大语言模型(如GPT-4o)等。相比于多模态视觉生成模型,CLIP等模型虽然也存在一定的数据泄露风险,但主要集中在分类等判别任务上,其生成能力较弱,因此数据泄露风险也较小。此外,多模态大语言大模型的数据抽取主要集中在语言数据,这在前文已详细论述。因此,本章节将重点关注文生图生成扩散模型中的数据抽取(数据记忆)问题。
7.6.1. 扩散模型记忆理解¶
Somepalli 等人 (Somepalli et al., 2022) 首先证明了扩散模型(包括像素空间和潜空间扩散模型)会记忆训练集中的图片。他们发现,尽管典型的大规模模型生成的图像在特征抽取器检测下不会完全复制训练集内容,但经常出现与训练集高度相似的图像,这类图像约占 Stable Diffusion 生成图像的 1.88%。起初,研究者将这种现象归因于数据集中的重复数据。虽然 Naseh 等人 (Naseh et al., 2023) 发现物体和单词上的重复也会引发这种记忆现象,但 Somepalli 等人 (Somepalli et al., 2023) 发现,除了数据重复外,条件生成也是触发记忆现象的重要因素。
为了进一步研究这个现象,Gu 等人 (Gu et al., 2023) 在CIFAR-10数据集上进行大量实验来探究影响模型记忆的因素。 为了探索各个因素的影响,他们首先定义有效模型记忆化然后基于该指标进行实验探究。
定义 7.1(有效模型记忆化)有效模型记忆(EMM)是相对于概率分布 \(P\)、模型\(\mathcal{M}\)和训练过程\(\mathcal{T}\)以及参数\(\epsilon > 0\) 定义的:
其中, \(\mathcal{R}_{\mathrm{Mem}}\) 表示记忆化比率。
上述定义假设较高的记忆化比率倾向发生在更小规模的训练数据集上, 这可以表述为:
假设 7.1(有效模型记忆化)给定模型 \(\mathcal{M}\)、训练过程\(\mathcal{T}\)和两个来自相同数据分布\(P\)的训练数据集\(D_1\)和\(D_2\), 如果\(D_1\subset D_2\), 则记忆化比率满足:
基于假设7.1, Gu 等人 (Gu et al., 2023) 提供了一种可行的 EMM 估计方法。具体而言, 从数据分布 \(P\)中采样一系列大小不同的训练数据集\(D_1,D_2,...\), 并按照训练过程\(\mathcal{T}\)训练相应的扩散模型\(\mathcal{M}\)。然后, 评估记忆化比率\(\mathcal{R}_{\mathrm{Mem}}(D_1, \mathcal{M}, \mathcal{T})\) \(\mathcal{R}_{\mathrm{Mem}}(D_2, \mathcal{M}, \mathcal{T}),...\), 并确定满足\(\mathcal{R}_{\mathrm{Mem}}(D, \mathcal{M}, \mathcal{T})\approx1-\epsilon\)的训练数据集大小\(D\)。精确确定 EMM 的值是不可行的。因此, EMM 的估计值为满足\(\mathcal{R}_{\mathrm{Mem}}(D_{i}, \mathcal{M}, \mathcal{T})>1-\epsilon\)和\(\mathcal{R}_{\mathrm{Mem}}(D_{i+1}, \mathcal{M}, \mathcal{T})<1-\epsilon\)的两个连续采样数据集\(D_i\)、\(D_{i+1}\) 之间的值。
基于EMM指标,可以量化不同因素对模型记忆的影响,以下是实验分析得到的影响扩散模型记忆的关键因素:
图像分辨率:数据维度对扩散模型的记忆有着深远影响。对于 \(32\times32\)的输入分辨率, EMM 约为\(1\text{k}\)。当分辨率为\(16\times16\)时,EMM 略超过\(4\text{k}\),而对于\(8\times8\)的分辨率,EMM达到约 8k。此外,即使在\(|D|=16\text{k}\)的情况下,在训练\(8\times8\)分辨率的CIFAR-10 图像时,记忆率仍超过\(60\%\)。
类别数量:多样性能够减少EMM但是影响不大。研究人员考虑了四种不同的数据分布,通过从 CIFAR-10 中选择 \(C\in\{1, 2, 5, 10\}\)个类别的图像来进行 EMM 评估。随着类别数量的增加,扩散模型倾向于表现出较低的记忆率和较低的 EMM,这与多样化数据更难被记忆的直觉一致。但需要注意的是,这种影响在小规模数据集上较小,因为\(C=5\)和\(C=10\) 观察到的 EMM 几乎相同。
类内多样性:类内多样性对记忆的贡献有限。 研究人员只使用 CIFAR-10 的 “Dog” 类进行实验。为了控制这种多样性, ImageNet 中的 “Dog” 类图像被逐步添加到 CIFAR-10 的 “Dog” 类中。ImageNet 数据的增加导致训练的扩散模型的 EMM 略有下降。与类别数量实验的结果类似,这种类内多样性对记忆的贡献有限。
模型宽度:模型宽度与扩散模型中的记忆化之间存在直接关系。研究人员探讨了不同的通道乘数(\(\{128, 192, 256, 320\}\))对最后结果的影响。随着扩散模型的宽度增加,EMM表现出单调递增的趋势。将通道乘数增加至\(320\)可以产生约\(5\text{k}\)的 EMM,相比通道乘数为\(128\) 时观察到的 EMM 增加了四倍。这些结果表明模型宽度与扩散模型中的记忆化之间存在直接关系。
模型深度:模型深度与扩散模型中的记忆化之间存在着非线性的关系。研究人员通过调整每个分辨率的残差块数量(从 \(2\)到\(12\))来改变模型深度。当将每个分辨率的残差块数量从\(2\)增加到\(6\) 时,EMM 会初步增加。但是,进一步增加模型深度,EMM 开始下降。
跳跃连接:相较于低分辨率连接,高分辨率下的跳跃连接对记忆化起到更为关键的作用,并且跳跃连接的数量和最后记忆的效果影响不大。研究人员发现即使跳跃连接数量被大大减少,训练好的扩散模型也能维持与完全跳跃连接相当的记忆化比率。进一步实验发现,位于较高分辨率的跳跃连接对记忆化贡献更大。有趣的是,跳跃连接数量的增加并不能始终带来更高的记忆化比率。例如,DDPM++ 模型在 \(16\times16\) 分辨率上具有 3 个跳跃连接,其记忆化比率低于 1 或 2 的情况。
时间信息嵌入:时间嵌入对记忆化也有着重要影响。研究人员进行了实验来测试随机傅里叶特征嵌入和位置嵌入方法,并评估它们对记忆化的影响。实验发现,在 DDPM++ 中使用傅里叶特征会显著降低记忆化比率(因此也降低了 EMM),突出了时间嵌入对记忆化的重要影响。
类别条件:相比无条件(unconditional)模型,有条件(conditional)扩散模型表现出更高的记忆化比率。即便是使用随机标签,扩散模型的记忆化水平与使用真实标签的模型相似。
随机标签类别数量:记忆化程度随着随机标签类别数量的增加而增加。当使用随机标签作为条件时,类别数 \(C\)不再局限于 CIFAR-10 的 10 类。因此,研究人员调节\(C\)的取值,并观察其对记忆化比率的影响。他们发现无条件扩散模型和\(C=1\)的有条件模型保持了相似的记忆化比率。然而,随着引入更多类别,扩散模型的记忆化明显增加。 最后,研究人员考虑一种极端情况,即每个训练样本在\(D\)中被分配一个唯一的类别标签,这可视为\(C=5\)k 的特殊情况。研究人员比较了在有条件扩散模型训练过程中,这种唯一类别条件和其他\(C\)值的记忆化比率,在仅\(8\text{k}\)个 epoch 内,使用唯一标签的扩散模型就达到了超过\(95\%\) 的记忆化比率。
7.6.2. 扩散模型数据抽取¶
7.6.2.1. 暴力抽取¶
在白盒设置下,最直接的数据抽取方法是通过模型随机生成大量图像,并将每张图像与训练图像进行比对,识别出重复的图像。这些重复图像即为抽取到的图像。Carlini 等人 (Carlini et al., 2023) 使用类似的暴力抽取方法,从 Stable Diffusion 中抽取了与训练数据集高度相似的图像。相比之下,前文提到的研究 (Somepalli et al., 2022) 只能抽取语义上记忆的图像,无法识别高相似的训练数据集图像。具体而言,暴力抽取方法包括以下两个步骤:
生成大量样本:使用可能触发记忆现象的文本描述引导 Stable Diffusion 生成图像。
执行成员推理:将新生成的图像与训练样本进行比对,区分出记忆中的图像。
成员推理 步骤旨在识别那些可能是记忆图像的生成图像。Carlini 等人 (Carlini et al., 2023) 提出了一个无需训练的方法,该方法基于以下假设:记忆图像生成的图像在不同随机种子下应非常相似。该方法为每个文本提示生成 500 张图像,这些图像使用不同(但未知)的随机种子生成。通过在这些 500 张生成图像之间构建一个图,如果 \({\boldsymbol{x}}_i \approx_{d} {\boldsymbol{x}}_j\),则连接图像\(i\)和\(j\)。如果图中最大团的大小至少为 10(即至少有 10 张图像几乎相同),则预测这些图像可能是记忆中的图像。 该方法使用 \(L_2\)距离来度量图像之间的相似性\(d\)。然而,生成的图像经常因\(L_2\)距离(如灰色背景)而被错误地认为相似。因此,该方法将每个图像分成 16 个不重叠的\(128 \times 128\)图块,并将两个图像之间所有图块对的最大\(L_2\)距离作为距离度量\(d\)。

图7.6.1 抽取数据示例:上面为原始数据,下面为生成数据 (Carlini et al., 2023) 。¶
抽取结果 图7.6.1 展示了一组抽取的图像,这些图像几乎以像素精度完美再现。所有图像的 \(L_2\)差异均在\(0.05\)以下(相比之下,将 PNG 图像重新编码为质量级别为 50 的 JPEG 时,平均\(L_2\)差异为\(0.02\))。
7.6.2.2. SIDE抽取方法¶
Chen 等人 (Chen et al., 2024) 基于上述研究,从理论上分析并证明了为什么条件扩散模型更容易触发模型记忆。他们提出了“潜在条件”这一概念,并基于此概念提出了SIDE(Surrogate Conditional Data Extraction)攻击方法。SIDE 可以从条件扩散模型中抽取训练数据,并在不同规模的 CelebA 数据集上将攻击的平均有效性提高了50%。下面将详细介绍其理论分析和SIDE抽取算法。
生成模型记忆理论分析 Chen 等人 (Chen et al., 2024) 提出了记忆度量(memorization metric)来量化模型记忆,并介绍了信息标签(Informative Label)概念,以从理论上探究为什么条件扩散模型更容易触发模型记忆。
记忆度量通过生成分布与以每个数据点为中心的分布之间的重叠程度来量化固定训练数据点的记忆。具体而言,给定一个参数为 \(\theta\)的生成模型\(f_{\theta}\)和训练数据集\(D = \{{\boldsymbol{x}}_i\}_{i=1}^N\),记忆度量\({\mathcal{M}}(D; \theta)\) 计算公式如下:
其中,\({\boldsymbol{x}}_i \in \mathbb{R}^d\)是第\(i\)个训练样本,\(N\)是训练样本的总数,\(p_{\theta}({\boldsymbol{x}})\)是生成样本的概率密度函数(PDF),\(q({\boldsymbol{x}}, {\boldsymbol{x}}_i, \epsilon)\)表示训练数据点\({\boldsymbol{x}}_i\)的概率分布。注意,\(q({\boldsymbol{x}}, {\boldsymbol{x}}_i, \epsilon)\)可能不是真实的数据分布,例如,它可以是以\({\boldsymbol{x}}_i\)为中心的狄拉克\(\delta\)函数:\(q({\boldsymbol{x}}, {\boldsymbol{x}}_i, \epsilon) = \delta({\boldsymbol{x}} - {\boldsymbol{x}}_i)\)。在式 (7.6.3) 中,\({\mathcal{M}}(D;\theta)\)的值越小(接近于零)表示记忆程度越高。
然而,研究者未使用狄拉克\(\delta\)函数作为\(q({\boldsymbol{x}}, {\boldsymbol{x}}_i, \epsilon)\),因为它在KL散度框架下不可计算。作为替代,研究者使用协方差矩阵为\(\epsilon *I*\)(其中\(*I*\)是单位矩阵,\(0 < \epsilon < 1\)是一个小的正标量)的高斯分布来定义\(q({\boldsymbol{x}}, {\boldsymbol{x}}_i, \epsilon)\):
基于上述定义,研究者从信息标签的角度建立理论理解。尽管在先前的工作 (Gu et al., 2023) 中,信息标签被讨论为类别标签,但在此处,他们定义了一个更广泛的版本,其中类别标签和随机标签都是其特殊情况。 设 \({\mathcal{Y}} = \{y_1, y_2, \cdots, y_C\}\)为训练数据集\(D\)的标签集,包含\(C\)个唯一标签。这些标签不仅限于传统的类别标签,还可以是文本、共享特征或用于将训练样本分组的聚类信息。设\(y_i\)为与\({\boldsymbol{x}}_i\)相关联的标签,\(D_{y=c} = \{{\boldsymbol{x}}_i \mid {\boldsymbol{x}}_i \in D, y_i=c\}\)是共享标签\(y=c\) 的训练样本子集。信息标签的定义如下:
定义 7.2(信息标签)如果标签\(y=c\)满足\(|D_{y=c}| < |D|\),则称其为信息标签。
上述定义表明,信息标签应能将一部分样本与其他样本区分开。一个极端情况是所有样本具有相同的标签,这种标签不具备信息性。信息标签包括显式标签(如类别标签、随机标签和文本)和隐式标签(如深度表征聚类)。类别标签和随机标签都是信息标签的特殊情况。
接下来,研究者探讨了信息标签与生成模型潜在空间中的类别聚类效应之间的关系。 假设有一个编码器 \(f_{\theta_{E}}({\boldsymbol{x}})\)和一个解码器\(f_{\theta_{D}}({\boldsymbol{z}})\)。编码器将数据样本\({\boldsymbol{x}} \in D\)映射到潜在空间\({\boldsymbol{z}}\),假设\({\boldsymbol{z}}\)服从正态分布\({\mathcal{N}}(\mathbf{{\boldsymbol{\mu}}}, \mathbf{{\boldsymbol{\Sigma}}})\):\(p_{\theta}({\boldsymbol{z}}) = {\mathcal{N}}(\mathbf{{\boldsymbol{\mu}}}, \mathbf{{\boldsymbol{\Sigma}}})\)。对于\({\boldsymbol{x}}_i \in D_{y=c}\),编码器将\({\boldsymbol{x}}_i\)映射到服从\({\mathcal{N}}(\mathbf{{\boldsymbol{\mu}}_c}, \mathbf{{\boldsymbol{\Sigma}}_c})\)的潜在分布\({\boldsymbol{z}}_c\),即\(p_{\theta}({\boldsymbol{z}} \mid y=c) = {\mathcal{N}}(\mathbf{{\boldsymbol{\mu}}_c}, \mathbf{{\boldsymbol{\Sigma}}_c})\)。解码器\(f_{\theta_{D}}({\boldsymbol{z}})\)将\({\boldsymbol{z}}\)映射回原始数据样本\({\boldsymbol{x}}\)。标签\(y_i\)是数据样本\({\boldsymbol{x}}_i\)的标签。训练生成模型\(f_{\theta}\) 的目标是优化以下似然估计:
如果\(f_{\theta}\)在公式 (7.6.5) 定义的目标上收敛,那么对于条件为信息标签\(y=c\)的潜在空间\({\boldsymbol{z}}\),在合理假设下我们有以下两个性质:
其中,\(\|\cdot\|_*\)是核范数,较小的值表示由于矩阵奇异值之和较小而包含较少的信息。
在上述命题中,研究者的假设是\(p_{\theta}({\boldsymbol{z}}|y)\)作为条件分布,因此其包含的信息少于\(p_{\theta}({\boldsymbol{z}})\)。所以,\(p_{\theta}({\boldsymbol{z}}|y)\)的协方差矩阵的核范数小于\(p_{\theta}({\boldsymbol{z}})\)的核范数。 直观地说,式 (7.6.6) 意味着在信息标签\(y=c\)条件下,每个训练样本的潜在编码更集中在分布\(p_{\theta}({\boldsymbol{z}}|y=c)\)周围,而不是\(p_{\theta}({\boldsymbol{z}})\)周围。
先前的工作 (Gu et al., 2023) 揭示了信息标签的存在显著影响了条件生成模型的记忆行为。信息标签提供了关于数据的额外上下文或细节,从而帮助模型更有效地学习特定的数据特征。我们通过以下定理来形式化这一观察:
定理 7.1当条件于信息标签\(y\)时,生成模型\(f_{\theta}\)会出现更高程度的记忆,数学表达如下:
定理7.1表明,当条件于信息标签时,生成模型会生成一个与分布\(q({\boldsymbol{x}}, {\boldsymbol{x}}_i, \epsilon)\)有更多重叠的数据分布,导致更多的记忆和更低的\({\mathcal{M}}({\mathcal{D}};\theta)\)(积分KL散度)值。
SIDE抽取算法 在无条件扩散模型中不存在显式的信息标签。然而,上述理论分析表明,即使在生成模型无条件训练的情况下,信息标签也可能会出现。在这种情况下,信息标签可能是隐式的,比如在训练过程中形成的聚类中心。研究者为无条件扩散模型构造隐式信息标签,将这些隐式标签转换为显式标签,然后利用这些显式标签从无条件扩散模型中抽取训练数据。 可以使用能够在扩散模型的采样过程中识别隐式标签\(y_I\)的分类器,来为扩散模型条件化隐式标签。该分类器可以是在与目标扩散模型相同数据上训练的普通分类器。当无法获得这样的分类器时,理论分析表明,随机标签或由预训练特征抽取器(如CLIP图像编码器)抽取的聚类信息也可以用作隐式标签。
假设无条件扩散模型学习了一个隐式标签\(y_{I}\)。那么,扩散模型的采样过程可以表示如下:
其中,\({\boldsymbol{x}}\)表示状态向量,\(f({\boldsymbol{x}}, t)\)表示漂移系数,\(g(t)\)是扩散系数,\(\nabla_{{\boldsymbol{x}}} \log p_{\theta}^{t}({\boldsymbol{x}})\)表示在时间\(t\)给定\({\boldsymbol{x}}\)的神经网络\(p_{\theta}\)的梯度,该神经网络被训练以近似真实数据分布\(p({\boldsymbol{x}})\)。\(\mathrm{d}w\)对应维纳过程的增量。\(\nabla_{{\boldsymbol{x}}} \log p_{\theta}^{t}(y_I | {\boldsymbol{x}})\)表示给定\(x\)时\(y_I\)的条件分布的梯度。
为了获得隐式标签的梯度,研究者使用生成隐式标签的分类器来近似梯度。然而,正如 (Guo et al., 2017) 所证明的,神经网络分类器倾向于校准不当。具体来说,分类器可能对其输出过于自信或信心不足。为了减轻分类器校准不当对采样过程的潜在影响,研究者引入了一个超参数\(\lambda\),使用幂先验在扩散路径上校准分类器的概率输出,如下所示:
然后,可以得到:
研究者注意到在式 (7.6.10) 中,分类器被表示为\(\log p_{\theta}^{t}(y | {\boldsymbol{x}})\),这暗示了它的时间依赖性。然而,根据他们的假设,他们只有一个与时间无关的分类器,而没有时间依赖的分类器。 为了解决这个问题,研究者进一步提出了一种名为时间依赖知识蒸馏(Time-Dependent Knowledge Distillation,TDKD)的方法来训练时间依赖的分类器。蒸馏过程如 图7.6.2 所示。TDKD在采样过程中为分类器模型提供时间依赖的指导,分两步进行:首先,调整网络架构以适应时间依赖的输入;其次,创建一个生成数据集和相关标签,以促进从普通分类器到其时间依赖对应物的知识蒸馏。
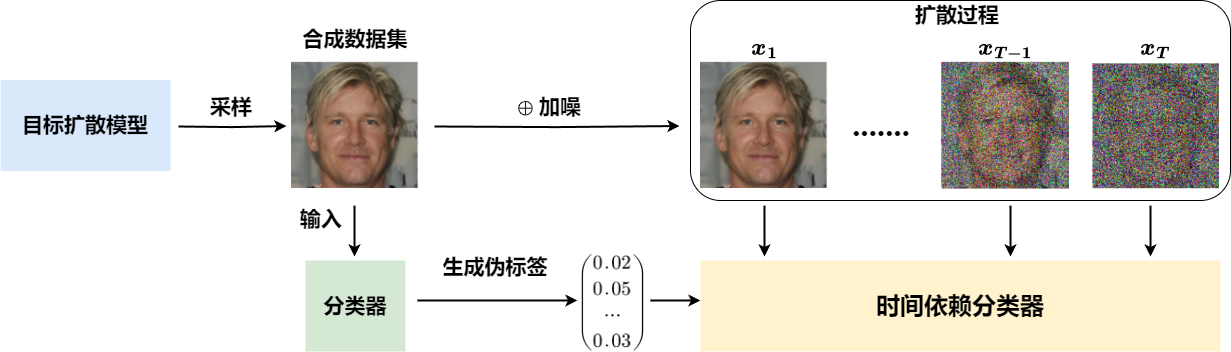
图7.6.2 时间依赖知识蒸馏(TDKD)示意图 (Chen et al., 2024) ,该方法在伪标记的合成数据集上训练一个时间依赖分类器。¶
具体来说,研究者在每个基本模块中加入了一个简单的时间依赖模块来改进网络架构。由于原始训练数据集未知,研究者采用目标扩散模型生成合成数据集。然后,使用在原始数据集上训练的普通分类器为生成的图像生成伪标签。最后,修改普通分类器的架构,添加时间依赖模块,并在标记的合成数据集上训练时间依赖分类器。这个训练的目标是最小化以下损失函数:
这种方法允许研究者创建一个时间依赖的分类器,该分类器可以在扩散模型的采样过程中提供更准确的引导,同时保持与原始分类器的一致性。通过这种方式,可以能够更好地利用隐式标签来改进数据抽取过程。
基于训练好的时间依赖分类器\(p_{\theta}^t(y|{\boldsymbol{x}}_t)\)和目标扩散模型,研究者使用SIDE方法通过条件生成过程从扩散模型中抽取训练数据。假设条件于标签\(y=c\)。首先,选择一组\(\lambda\):\(D_{\lambda}\)来进行SIDE攻击,为\(D_{\lambda}\)中的不同\(\lambda\)采样\(N_G\)个数据样本。 在每个采样时间步\(t\),研究者计算梯度\(\nabla_{{\boldsymbol{x}}_t} \mathcal{L}_{CE}(c,p_{\theta}^t(y|{\boldsymbol{x}}_t))\)(其中\(\mathcal{L}_{CE}(\cdot)\)是交叉熵损失)。然后,使用该梯度和扩散模型来逆转扩散过程。第三,计算每个生成图像的相似度分数。最后,使用某些评估指标来评估攻击性能,并将不同\(\lambda\)的性能平均作为最终结果。 图7.6.3 展示了SIDE方法抽取到的图像。

图7.6.3 SIDE方法从在CelebA数据集子集上训练的DDPM中抽取的图像示例 (Chen et al., 2024) :上方为训练图像;下方为抽取图像。¶
7.6.3. 扩散模型数据记忆检测¶
Wen 等人 (Wen et al., 2024) 和 Webster等人 (Webster, 2023) 发现,如果扩散模型记忆某一个提示词对应的图像,那么扩散模型一步去噪后的图片和一步去噪前的图片(原始噪声)有着很大的\(L_2\)距离,基于这个发现,两篇文章独立地提出了对于扩散模型数据记忆检测的方法。值得注意的是,虽然Webster等人 (Webster, 2023) 在原论文中称他们的方法是抽取方法,但是该方法本质上来说是一种检测方法,因为其主要是更高效地检测暴力抽取 (Carlini et al., 2023) 出来的图片是否是记忆图片。
白盒模型记忆检测 在白盒设定下,研究者 (Webster, 2023) 假设攻击者同时拥有训练集中的图片文字标注和模型参数。在生成时,条件扩散模型从高斯分布\(\epsilon \sim N(0,1)\)中抽取一个样本,然后使用去噪自编码器\(D(z_{t},c)\)将噪声\(z_{t}\)恢复成真实样本\(z_{0}\)。研究者提出了一个易于计算的指标,该指标可以通过测量\(D(\sigma_{T} \epsilon,c)\)对噪声的修改程度来判断生成图片是否是记忆图片,指标定义如下:
其中,\(\sigma_{1}\)根据 (Crowson, 2022) 中实现的Heun采样器以一个时间步进行初始化。研究者将这个误差称为去噪置信度分数(Denoising Confidence Score,DCS)。可以进一步使用阈值\(\tau_{\mathrm{DCS}}\)将其转换为二元分类器:
尽管此方法是一个白盒方法,但其实际上并不需要访问扩散模型的参数,只需要噪声生成过程。而对于潜在扩散模型,此方法只需要第一阶段的下采样编码器。
黑盒模型记忆检测 在黑盒设定下,攻击者拥有图片文字标注,但只能调用扩散模型根据文字生成图像\(Gen(c,r)\),其中\(c\)是图片文字标注,\(r\)是随机种子。 此外,假设攻击者能够控制时间步\(T\)(如Midjourney),使用\(Gen(c,r,T=1)\)来生成图像。这是因为他们注意到经过第一步迭代的非记忆图像通常是高度模糊的图像。与具有清晰边缘的记忆图像相比,模糊图像没有一致的边缘(或根本没有边缘)。因此,研究者采用了一种简单的图像处理技术,首先计算图像边缘,然后查找这些相同边缘在其他种子中出现的一致性。令算子\(Edge()\)通过对空间梯度的幅度进行阈值处理(如使用Sobel滤波器)输出二值图像,并定义边缘一致性分数(Edge Consistency Score,ECS)如下:
其中,\(J\)是随机种子数量,\(\gamma\)是一个预定义的阈值。尽管该方法非常简单,但在实际中取得了不错的检测效果。
7.6.4. 扩散模型记忆神经元定位¶
NeMo方法 Hintersdorf 等人 (Hintersdorf et al., 2024) 发现负责记忆的神经元与非记忆神经元在激活模式上存在差异,删除记忆神经元可以消除模型记忆。基于这些发现,他们提出了 NeMo 方法来定位负责记忆的神经元,过程如下:
初步选择:首先,识别可能负责记忆特定训练样本的候选神经元。这个初步选择是粗略的,旨在加速计算,可能包含假阳性神经元。研究者发现,记忆提示词的激活模式与非记忆提示词不同,因此他们将记忆神经元定义为那些表现出异常(OOD)激活行为的神经元。他们在一个单独的非记忆提示词保留集上识别神经元的标准激活行为,然后比较记忆提示词的神经元激活模式,从中识别出具有 OOD 行为的神经元。 设交叉注意力层为 \(l \in \{1, \ldots, L\}\),第\(l\)层第\(i\)个神经元对提示词\(y\)的激活表示为\(a_i^l(y)\)。设\(\mu_i^l\)为该神经元的预计算平均激活,\(\sigma_i^l\)为标准差。为了检测可能负责记忆提示词\(y\)的神经元,他们计算标准化\(z\) 分数:
(7.6.15)¶\[z_i^l(y) = \frac{a_i^l(y) - \mu_i^l}{\sigma_i^l}\]为识别是否表现出 OOD 激活行为,他们设置阈值 \(\theta_{act}\),若\(|z_i^l(y)| > \theta_{act}\),则认为第\(l\)层中的神经元\(i\)具有 OOD 行为。阈值\(\theta_{act}\)越低,标记为 OOD 的神经元越多。初步选择时,他们从较高的\(\theta_{act}=5\)开始,计算所有神经元的\(z\)分数,停用所有满足\(|z_i^l(y)| > \theta_{act}\)的神经元,若记忆分数仍未低于阈值\(\tau_{mem}\),则逐步降低阈值\(\theta_{act}\)直至达到目标记忆分数\(\tau_{mem}\)。
细化集合:在细化步骤中,过滤掉初步选择中不真正负责记忆的神经元。首先,将初步选择的神经元集合 \(S_{refined} = S_{initial}\)按层分组,得到每层\(l\)的神经元集合\(S_{refined}^l\)。遍历每层\(l\),重新激活层\(l\)中所有已识别的神经元\(S_{refined}^l\),同时保持其他层的神经元停用,计算基于 SSIM (Wang et al., 2004) 的记忆分数,检查其是否仍低于阈值\(\tau_{mem}\)。若记忆分数未超阈值\(\tau_{mem}\),则认为层\(l\)的候选神经元\(S_{refined}^l\)不为记忆神经元,并从\(S_{refined}\) 中移除。 然后,单独检查 \(S_{refined}\)中的每个神经元,重新激活该神经元,保持其他神经元停用。如果在停用神经元上计算的记忆分数不超过\(\tau_{mem}\),则从\(S_{refined}\)中移除该神经元。遍历所有神经元后,剩余的神经元即为记忆神经元,最终集合为\(S_\text{final}\)。
7.6.5. 视觉语言模型记忆¶
Pinto 等人 (Pinto et al., 2024) 发现视觉语言模型(VLM)可能记忆敏感的隐私信息。他们首先定义了“可抽取性”,即从图像中的某段文本 \(a\)的部分上下文中是否可以抽取正确答案\(a\)。基于这一概念,他们发现 VLM 能记忆个人身份信息,并探究了影响 VLM 记忆的因素。
定义 7.3(上下文中答案可抽取性)给定一个模型 \(f\)和一个样本\((I, Q, a) \in D\),如果正确答案\(a\)可以从部分上下文\((I^{-a}, Q)\)中获得,即\(f(I^{-a}, Q) = a\),则称为可抽取样本,其中\(I^{-a}\)是图像\(I\)中答案\(a\) 被移除后的副本。
研究者通过在训练数据集中使用 Tesseract (Smith, 2007) OCR 输出获得部分图像 \(I^{-a}\),识别与文档中所有出现的答案\(a\) 相关的边界框,并用白色方框替换它们。这种方法使得从训练集中识别实际可抽取的敏感样本变得容易。研究发现,VLM 能轻易抽取在包含约 40K 个样本的训练集中仅出现一次或两次 的个人身份信息。
研究发现以下因素影响 VLM 的记忆抽取:
输入图像中是否存在文字:图像中缺少文字显著降低了模型返回正确答案的能力。当没有文本时,模型更容易依赖预训练阶段获得的通用知识。图像中缺少文字显著降低了模型的回答准确率。
询问文字是否存在转义情况:转义后的文字不会阻止攻击者抽取敏感信息,但会减少可抽取样本的数量。
输入图像中的干扰:可抽取样本对亮度扰动相对稳健,但对空间变换的稳健性较低。攻击者不需要完美复制原始训练图像即可抽取训练数据集中的信息。
输入信息的模态:在少数情况下,模型仅凭语言组件即可抽取敏感答案。如果训练答案不在图像模态中,且特定文档的问题在训练时未出现,则仅凭图像不足以抽取记忆中的答案。
7.7. 成员推理¶
近年来,随着扩散模型的广泛应用,训练数据的隐私安全问题成为了研究的重点。特别是成员推理攻击(Membership Inference Attacks, MIAs)引起了广泛关注。这种攻击手段通过分析模型的输出行为,判断特定数据是否属于模型的训练集。对于扩散模型来说,攻击者可能利用其强大的学习和记忆能力实施精确高效的成员推理攻击,这对数据隐私安全构成严重威胁,并对模型的安全性提出了更高的要求。
本章节将探讨针对图像生成模型的成员推理攻击,包括扩散模型的成员推理攻击和适用于一般图像生成模型的攻击方法。
7.7.1. 扩散模型成员推理¶
成员推理攻击的目标是判断给定样本是否属于模型的训练集,即是否为训练集的“成员”。假设模型为 \(f_\theta\),其参数为\(\theta\),训练数据集\(D=\{{\boldsymbol{x}}_1, \cdots, {\boldsymbol{x}}_n\}\)从分布\(q_{data}\)中采样而来,其中\(D\)被分为训练集\(D_M\)和测试集\(D_T\),模型由\(D_M\)训练得到。在这种情况下,\(D_M\)中的样本称为“成员”(member),而\(D_T\)中的样本称为“非成员”(non-member)。每个样本\({\boldsymbol{x}}\)都有一个标签\(m\),指示其是否为成员:如果样本\({\boldsymbol{x}}_i\)属于成员,则\(m_i = 1\);否则\(m_i = 0\)。攻击者使用某种攻击算法\(\mathcal{M}\)判断样本\({\boldsymbol{x}}_i\) 是否为成员:
其中,\(\mathbb{1}\)是指示函数,\(\tau\)是阈值。如果算法输出\(\mathcal{M}({\boldsymbol{x}}_i, \theta) = 1\),则认为\({\boldsymbol{x}}_i\)是“成员”;如果输出为\(\mathcal{M}({\boldsymbol{x}}_i, \theta) = 0\),则认为其“不属于成员”。成员推理攻击的评价指标与二分类模型类似,包括准确率、ROC 曲线和 AUC 等。
单步误差比较成员推理 针对扩散模型的成员推理攻击面临两大挑战:(1)扩散模型具有更强的泛化能力;(2)现有方法未考虑扩散模型的特性。 为应对这些挑战,研究人员提出了单步误差比较成员推理(Step-wise Error Comparing Membership Inference,SecMI)攻击方法 (Duan et al., 2023) ,利用扩散模型的独特性质进行精确和高效的推理。
扩散模型的原始架构包括 \(T\)步前向加噪过程\(q({\boldsymbol{x}}_{t}|{\boldsymbol{x}}_{t-1})\)和\(T\)步逆向去噪过程\(p_{\theta}({\boldsymbol{x}}_{t-1}|{\boldsymbol{x}}_{t}), (1 \leq t \leq T)\) (Ho et al., 2020) :
其中,\(\beta_1, \cdots, \beta_{T}\)是固定的变分规划(variance schedule)。这种结构的特点是每个时间点\(t\)的前向过程的边缘分布\(q({\boldsymbol{x}}_t | {\boldsymbol{x}}_0)\)在给定初始图像\({\boldsymbol{x}}_0\) 时具有统一形式:
其中, \(\alpha_t = 1 - \beta_t\),\(\bar{\alpha}_t=\prod_{s=1}^t{\alpha_s}\)。
常见的成员推理攻击方法通过损失函数来判断,形式如下:
其中,\(\mathcal{L}(\theta, {\boldsymbol{x}})\) 是交叉熵损失。这种方法的直觉是训练集成员的损失值应低于非训练集成员。
在扩散模型中,类似的训练目标是通过最小化证据下界(Evidence Lower Bound,ELBO)来逼近逆向过程 \(p_{\theta}({\boldsymbol{x}}_{t-1}|{\boldsymbol{x}}_{t})\) 的均值:
其中, \(\tilde{{\boldsymbol{\mu}}}_t ({\boldsymbol{x}}_t, {\boldsymbol{x}}_0)\)是前向扩散分布\(q({\boldsymbol{x}}_{t-1}|{\boldsymbol{x}}_t, {\boldsymbol{x}}_0)\)的均值,而\({\boldsymbol{\mu}}_{\theta}({\boldsymbol{x}}_t, t)\)是逆向分布\(p_{\theta}({\boldsymbol{x}}_{t-1}|{\boldsymbol{x}}_{t})\)的均值。公式 (7.7.5) 说明在固定样本\({\boldsymbol{x}}_0\) 的情况下的局部损失为:
其中, \({\boldsymbol{x}}_{t-1} \sim q({\boldsymbol{x}}_{t-1} | {\boldsymbol{x}}_{t}, {\boldsymbol{x}}_0)\),\(\hat{{\boldsymbol{x}}}_{t-1} \sim p_{\theta}(\hat{{\boldsymbol{x}}}_{t-1}|{\boldsymbol{x}}_{t})\),省略了常数系数\(\frac{1}{2\sigma_t^2}\)。
仅靠公式 (7.7.6) 还无法得到实际可行的方法,因为损失计算需要具体的分布,而传统的蒙特卡洛方法由于步长过长而非常耗时。为此,我们需要引入确定性扩散模型 (Song et al., 2020) 的思想,定义单步确定性前向和逆向过程:
其中:
以及多步前向和逆向过程:
最终的单步损失定义为:
公式 (7.7.11) 称为 \(\boldsymbol{t}\)-error。可以证明,当\(|| \epsilon_{\theta}({\boldsymbol{x}}_t, t) - \epsilon ||^2 \rightarrow 0\)时,\(\tilde{\mathcal{L}}_{t, {\boldsymbol{x}}_0}\)会收敛于 \(\mathcal{L}_{t, {\boldsymbol{x}}_0}\),其中 \(\epsilon \sim \mathcal{N}(0, I)\) 为标准高斯噪声。实际情况是:
因此,当 \(|| \epsilon_{\theta}({\boldsymbol{x}}_t, t) - \epsilon ||^2 \rightarrow 0\)时,\(\Delta_{t, {\boldsymbol{x}}_0}=\tilde{\ell}_{t, {\boldsymbol{x}}_0} \rightarrow \ell_{t, {\boldsymbol{x}}_0}\) 成立。
基于 \(t\)-error 损失,研究人员提出了两种 SecMI 方法的变体:
基于统计的 SecMI\(_{stat}\)方法:通过计算特定时间点\(t_{SEC}\)的\(t\)-error 损失进行判断:
(7.7.13)¶\[\mathcal{M}({\boldsymbol{x}}_0, \theta) = \mathbb{1}\left[ \tilde{\mathcal{L}}_{t_{SEC}, {\boldsymbol{x}}_0} \leq \tau \right]\]基于神经网络的 SecMI\(_{\mathit{NNs}}\)方法:通过训练一个神经网络模型\(f_{\mathcal{A}}\) 进行判断:
(7.7.14)¶\[\mathcal{M}({\boldsymbol{x}}_0, \theta) = \mathbb{1}\left[ f_{\mathcal{A}}( | \psi_{\theta}(\phi_{\theta}(\tilde{{\boldsymbol{x}}}_t, t), t) - \tilde{{\boldsymbol{x}}}_{t} | ) \leq \tau \right]\]
SecMI 方法巧妙地利用了扩散模型的结构特性,通过计算特定时间点的单步误差来判断训练集中的成员样本。这不仅揭示了扩散模型在隐私保护方面的潜在脆弱性,也为防御此类攻击提供了新的视角。
7.7.2. 模型无关成员推理¶
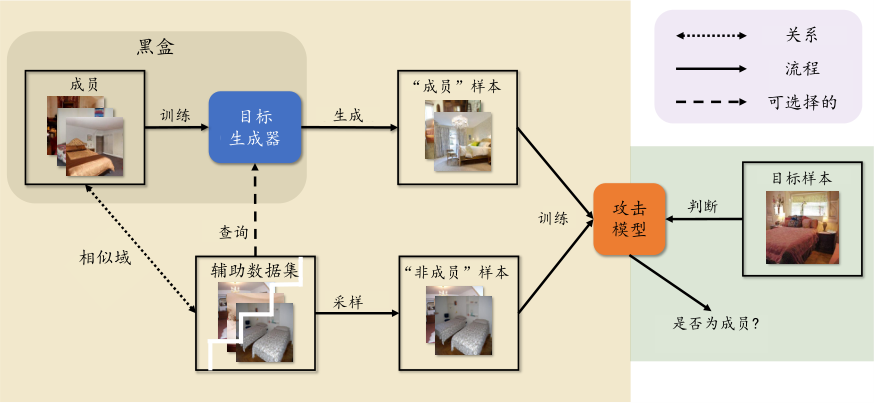
图7.7.1 模型无关成员推理流程图 (Zhang et al., 2024)¶
SecMI 方法可以高效地进行扩散模型的成员推理,但与其他模型特定的成员推理方法一样,它依赖于模型的特定性质。为了将成员推理攻击推广到一般的图像生成模型,研究人员提出了模型无关成员推理攻击 (Zhang et al., 2024) 。这种攻击方法基于生成模型的过拟合能力,即生成模型能够记忆并近似原始数据的分布,因此可以利用模型生成的输出分布进行通用、精确且高效的成员推理攻击。
如 图7.7.1 所示,模型无关的成员推理方法分为两个步骤:图像生成阶段和成员推理阶段。 其中,图像生成阶段至关重要,因为它决定了生成模型的输出分布与真实数据分布的接近程度。具体来说,模型无关的成员推理方法使用生成模型的输出分布来近似原始数据分布,并利用这些输出生成的数据集作为攻击模型训练集中的“成员”部分。同时,假设攻击者有一个与原始数据集 \(D_{train}\)相近的辅助数据集\(D_{aux}\)作为“非成员”部分。在条件生成模型中,\(D_{aux}\)被分为两个部分:\(D_{aux}^{in}\)和\(D_{aux}^{out}\),前者用于对生成模型进行查询,后者作为攻击模型的“非成员”输入。攻击者使用这些数据训练分类模型作为攻击模型,并用该模型对特定样本进行成员推理。本方法为黑盒攻击,不需要访问目标模型的内部参数或状态,只需模型的查询权限。
图像生成阶段:为了获取攻击模型的训练集,需要同时获得“成员”和“非成员”部分。已知“非成员”部分为:
(7.7.15)¶\[\Big\{({\boldsymbol{x}},\text{non-member}) \ \ |\ \ {\boldsymbol{x}}\in D_{aux}^{out}\Big\}\]问题在于如何获取“成员”部分。生成模型因其过拟合特性,会对训练数据的分布产生记忆,体现在其输出分布中。因此,可以用生成器的输出近似原始训练数据分布。对于无条件生成模型,可以通过对标准高斯噪声 \({\boldsymbol{z}} \sim \mathcal{N}({\boldsymbol{0}}, I)\) 进行查询得到:
(7.7.16)¶\[\Big\{({\mathcal{G}}_{target}({\boldsymbol{z}}),\text{member}) \ \ |\ \ {\boldsymbol{z}} \in {\mathcal{Z}}_{aux} \Big\}\]其中,\({\mathcal{Z}}_{aux} = \{{\boldsymbol{z}}_1, {\boldsymbol{z}}_2, \cdots, {\boldsymbol{z}}_n\}\)为从标准高斯分布中采样得到的噪声。对于条件生成模型,通过查询辅助数据集中的\(D_{aux}^{in}\) 得到:
(7.7.17)¶\[\Big\{({\mathcal{G}}_{target}({\boldsymbol{x}}),\text{member}) \ \ |\ \ {\boldsymbol{x}} \in D_{aux}^{in}\Big\}\]成员推理阶段:在此阶段,攻击者利用图像生成阶段获得的“成员”和“非成员”数据训练一个二分类器 \(\mathcal{A}\)。训练完成后,给定一个目标样本\({\boldsymbol{x}}_{query}\),攻击者输入该样本到攻击模型中,判断其是否属于目标模型的训练集(注意在整个推理阶段中,攻击者不需要对目标模型进行进一步查询):
(7.7.18)¶\[\mathcal{A}({\boldsymbol{x}}_{query}) \rightarrow y_{query}\]其中,\(y_{query}\in\{0,1\}\) 为判断结果。
模型无关的成员推理攻击方法利用生成模型对训练数据分布的记忆能力,通过生成模型的输出生成分布来近似真实数据分布。这使得攻击模型能够更好地学习到成员与非成员样本之间的区别。由于该方法只需目标生成模型的黑盒权限,并且不对生成模型的类型做进一步假设,因此可以广泛应用于包括 GAN、VAE 及 DDPM 等各种生成模型,从而实现一种模型无关、准确且高效的成员推理攻击。
7.8. 本章小结¶
本章详细探讨了基于多模态大模型的安全攻防研究,涉及对抗攻击、对抗防御、后门攻击、越狱攻击、数据抽取和成员推理等方面。首先,我们介绍了对抗攻击的基本概念和方法,包括针对CLIP模型和视觉语言模型的具体攻击策略,并强调了跨模型和跨提示词的可转移性。接着,我们讨论了对抗防御策略,如视觉语言对抗训练、对抗提示微调和对抗对比微调,以提高模型的鲁棒性。随后,我们分析了后门攻击技术,探讨了在CLIP模型和扩散模型中植入和防御后门的方法。越狱攻击部分介绍了通过图像模态、文本模态和图像-文本多模态的越狱攻击方法。我们还探讨了从多模态模型中抽取数据的技术,包括针对扩散模型和视觉语言模型的记忆理解和成员推理方法。通过本章的学习,我们深入了解了多模态大模型在实际应用中的安全挑战及其防御策略,为未来相关领域的研究和应用提供了宝贵参考。
7.9. 习题¶
请简述 对抗攻击方法AttackVLM 如何在黑盒环境中攻击多模态大模型。
请简单分析对抗攻击方法InstructTA 如何在仅能访问视觉编码器的情况下实现高可转移性的目标对抗攻击?
解释视觉语言对抗训练、对抗提示微调和对抗对比微调之间的区别与联系。
结合图像越狱和文本越狱攻击,讨论多模态模型在实际应用中的安全性挑战,并提出可能的防御策略。
从文生图扩散模型中可以抽取那些数据?分别面临什么样的挑战?